Go에서 GLFW 등을 이용해 그래픽스 관련 작업을 할 때에도 자동화
테스트 구성이 가능합니다. 하지만 GitHub Actions과 같이
디스플레이가 없는 환경에서는 의존성을 가지고 있다는 이유만으로 그래픽스 관련 테스트가 실패합니다.
xvfb는 메뉴얼에서 virtual framebuffer X server for X Version 라고 소개되고 있으며, 서버 사이드
테스트를 위해 주로 사용됩니다.
Ubuntu 기준으로 sudo apt install xvfb로 설치하고 xvfb-run에 이어서 테스트 명령어를 추가하여
테스트할 수 있습니다. 실제 GitHub Actions에 적용한 예시를
공유드립니다.
Dave Cheney의 The Zen of Go를 번역했습니다. 좀 더 알고 싶으신 분은 발표 영상과 블로그 글을 함께 참고해 주십시오.
Go의 철학
쉽고, 읽기 좋으며, 유지가능한 Go 코드 작성을 위한 10가지 엔지니어링 가치. 고퍼콘 이스라엘 2020에 발표하였음.
패키지는 하나의 목적만을 달성합니다
잘 디자인된 Go 패키지는 단 하나의 아이디어와 관련 동작을 제공합니다. 좋은 Go 패키지를 위해 좋은 이름을 먼저 정해야 합니다. 엘리베이터 피치라고 생각하며 패키지 이름을 정해보십시오.
에러는 명시적으로 처리합니다
단단한 프로그램은 문제가 생기기 전에 실패처리를 하는 요소들로 이루어져 있습니다. 실패를 발생지점에서 의도적으로 처리할 수 있다는 것은 if err != nil { return err } 의 장황함마저 대수롭지 않아 보이게 합니다. panic과 recover는 예외가 아니며, 그런 식으로 사용되게 의도되지 않았습니다.
gRPC 101
간단하고 빠르게 게임서버 만들기
gRPC
A high performance,
open source
universal
RPC framework
RPC(Remote procedure call)
원격 프로시저 호출
왜 gRPC 인가?
- Simple service definition
- Start quickly and scale
- Works across languages and platforms
- Bi-directional streaming and integrated auth
Simple service definition
강력한 바이너리 직렬화 툴셋인,
Protocol Buffers 를 활용해 서비스를 정의함
Start quickly and scale
적은 코드로 쉽게 개발을 시작한 후,
대규모 요청을 처리하게 확장가능
자동으로 생성되는 클라이언트, 서버 stubs 를 사용해
개요
쿠키런: 킹덤이 오픈 후 알 수 없는 이유로 오랜 시간 점검하였음
총 점검 시간: 39시간 40분(2021-01-25 16:50:00 ~ 2021-01-25 03:30:00)
원인
기술적인 원인은 공개하지 않았음
나중에라도 데브시스터즈에서 공유해주시면 흥미로울 것 같음
여러분께 <쿠키런: 킹덤>을 선보이며 여러 가지 상황에 대비할 준비를 해왔지만 이번에 발생한 오류는 예상치 못한 치명적인 문제였고, 킹덤팀에서도 오랜 시간을 들여 수정하게 되었습니다.
점검 보상
- 크리스탈 12,000개
- 스태미너 젤리 50개
- 킹덤 아레나 티켓 30개
- 코인 50,000개
- 가속원 30분 5개
- 경험의 별사탕 레벨 4 100개
긴급 점검 보상은 2021년 1월 25일(월) 점검 전까지 생성된 계정에 한하여 지급됩니다.
로블록스는 2021년 10월 28일부터 10월 31일까지 73시간의 장애 대한 디브리핑을 하고 자사 블로그에 공개했습니다.
최근의 개선사항과 계획된 작업들 중 인상적인 내용 몇가지를 기록합니다.
모니터링 시스템 개선
모니터링 시스템이 메인 시스템 간 순환 종속성 제거했습니다.
메인 시스템 장애가 모니터링 시스템 장애로 이어졌고, 그로 인해 장애 원인를 찾을 데이터를 빠르게 확보할 수 없었음
장애의 주 원인(Consul and BoltDB) 모니터링 시스템을 확장했습니다.
서비스 시작과 설정 관리방식 개선
서비스 재시작 시 서비스에 필요한 캐시 배치, 웜업을 위해 서비스 복구가 느려졌습니다.
이 프로세스를 자동화하고 오류가 덜 발생하게 하기 위해 도구와 프로세스를 개발하고 있습니다.
특히 캐시 배포 매커니즘을 재설계했습니다.
개요
2월 19일(금) 23:22 ~ 2월 20(토) 19:00 까지 쿠키런: 킹덤 긴급 점검이 있었습니다.
원인
아마존웹서비스 장애로 인한 긴급 점검이라고 안내하고 있습니다.
특이사항
동일한 원인(AWS 도쿄 리전 장애)으로 의심되는 리그 오브 레전드의 경우 2월 20일 00:45 에 정상화되었는데, 왜 19:00 까지
점검이 지속되었는지 궁금합니다. 아마 서버 아키텍처의 유연성 차이 또는 데이터베이스의 HA 구성 차이일 것으로 짐작됩니다.
참고자료
쿠키런: 킹덤 긴급점검이 있었습니다. 접속자 수 증대와 함께 증가하는 부하를 개선했는데, 어떤 작업이 있었는지 궁금합니다.
개요
- 업데이트를 위한 점검(06:00~11:00)
- 점검 내용: 길드 시스템, 신규 쿠키 추가 및 오류사항 수정 등
- 15:00시 서버 안정화를 위한 긴급 점검 시작
- 22:00시 긴급 점검 완료
채용공고에서 흥미로운 부분
우대조건에 아래와 같은 내용이 있는데 어떤 마음인지 알 것 같습니다.
try-catch 와 null 에 현실자각타임이 오신 분
평소 흥미롭게 보던 기술스택이 있습니다.
언리얼 엔진의 UE_LOG 매크로는 컴파일 시점에 입력값의 오류를 검사하지 않습니다.
따라서 실행 중 로그를 기록하려다 의도하지 않은 동작(크래시 등)을 발생시킬 위험이 있습니다.
예)
FString temp;
UE_LOG(LogClass, Log, TEXT("%d, %s"), *temp);
_stprintf_s
언리얼 엔진 4
커스텀 네비게이션 시스템
박재완
jaewan.huey.park@gmail.com
목차
- 네비게이션 시스템 개요
- 왜 커스텀이 필요한가?
- 커스텀 네비게이션 데이터 구현 맛보기
- 참고자료
- Q & A
네비게이션 시스템
인공지능 에이전트가 경로 찾기를 사용하여
레벨을 탐색하는 기능을 제공
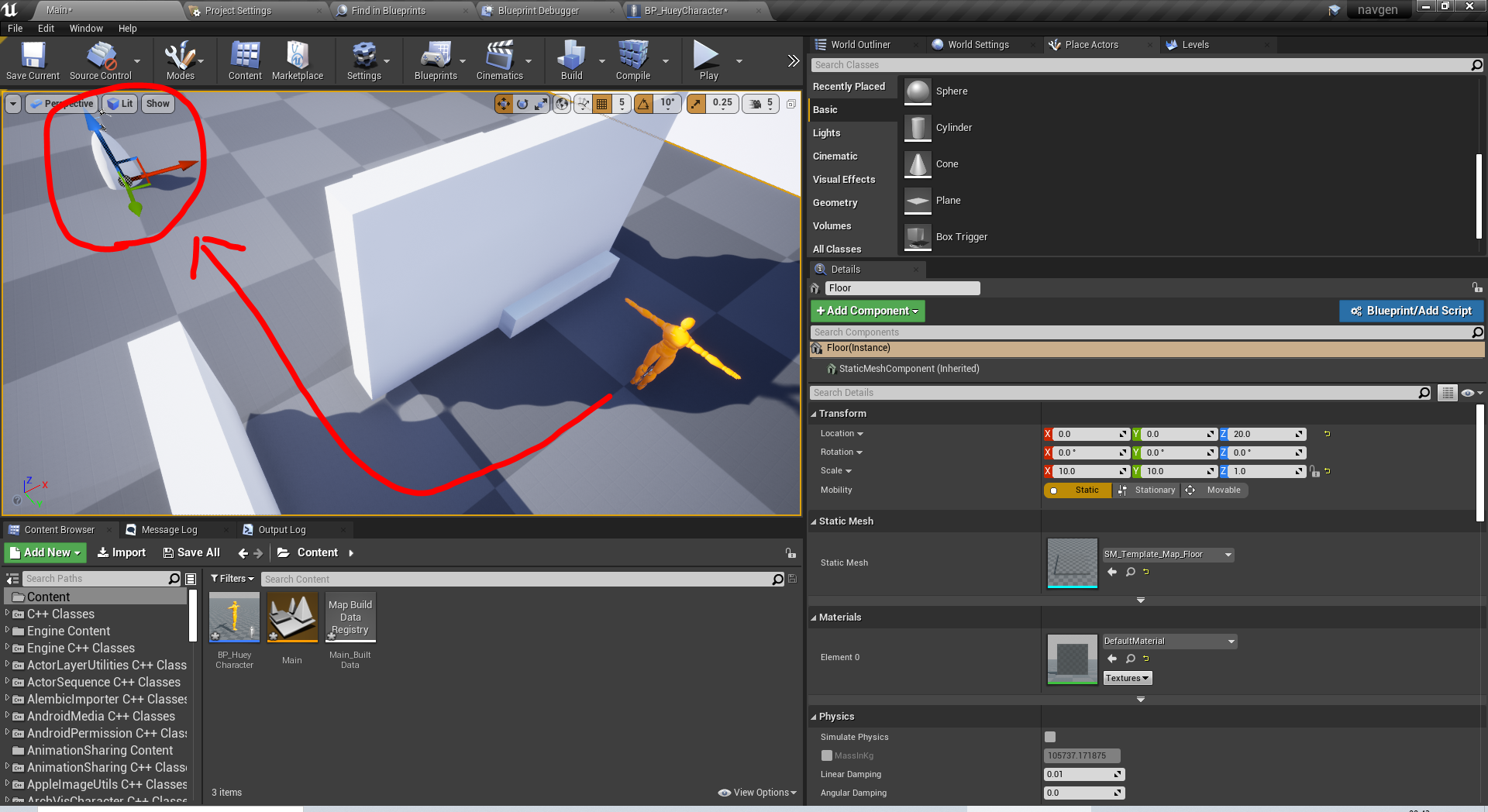
벽을 피해 목적지로 가고 싶다면?
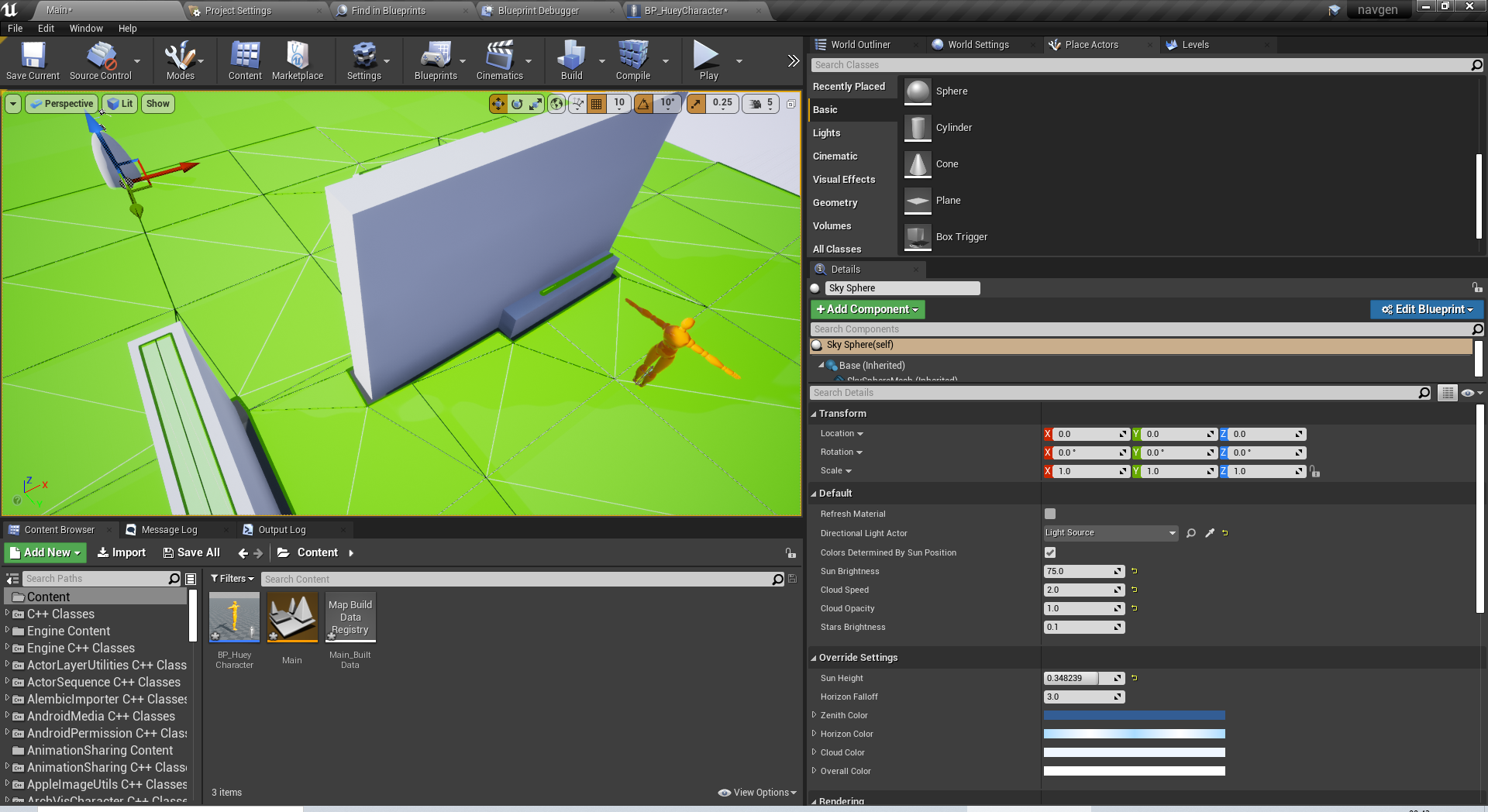
그냥 사용하시면 됩니다
왜 커스텀이 필요한가?
이유 1.
특별한 연출
언리얼 엔진 4 에 내장 네비게이션은
recastnavigation 기반
일반적인 상황에서 잘 작동하지만
특별한 연출을 보여주기엔 아쉬운 부분들이 있음