트랜잭션
몽고디비는 4.0버전(2018년)부터 여러 도큐먼트에 대한 트랜잭션을, 4.2버전(2019년) 부터는 샤딩된 컬렉션에 대한
분산 트랜잭션을 지원하고 있습니다.
여러 도큐먼트에 대한 ACID 트랜잭션 지원은 다양한 상황에서 개발자가 쉽게 대응할 수 있게 합니다. 스냅샷 격리수준과
아토믹한 실행은 샤딩된 클러스터에서도 트랜잭션이 필요한 워크로드를 제어할 수 있게 합니다.
- In version 4.0, MongoDB supports multi-document transactions on replica sets.
- In version 4.2, MongoDB introduces distributed transactions, which adds support for multi-document transactions on sharded clusters and incorporates the existing support for multi-document transactions on replica sets.
IMPORTANT: 대부분의 경우 멀티 도큐먼트 트랜잭션은 큰 부하를 일으키며, 효율적인 스키마를 대체하지 않아야 합니다.
대부분의 시나리오에서 비정규화된 데이터 모델(임베디드 도큐먼트 또는 배열)로 최적화 가능합니다.
인덱스
인덱스는 쿼리가 효율적으로 실행되게 돕습니다. 쿼리에 적절한 인덱스가 있으면 이를 사용해 조회할 도큐먼트 수를 줄일 수 있습니다.
인덱스는 특정 필드 또는 필드들을 값에 따라 정렬해 저장합니다.
정렬된 인덱스는 효율적인 레인지 쿼리를 지원합니다.
몽고디비 인덱스는 B-tree 자료구조를 사용합니다.

_id 인덱스
몽고디비는 _id 유니크 인덱스를 만듭니다.
_id 인덱스는 같은 _id 를 가진 도큐먼트가 두 개 생기는 것을 막습니다. _id 인덱스는 제거할 수 없습니다.
NOTE: 샤딩된 클러스터에서 _id 필드를 샤드 키로 사용하지 않으면 오류방지를 위해 애플리케이션이 _id 필드의
유니크성을 보장해야 합니다.
어그리게이션(Aggregation)
어그리게이션 작업은 데이터를 처리하여 계산된 결과를 반환합니다. 어그리게이션은 여러 도큐먼트의 값을 그룹화하고, 데이터에
다양한 작업을 수행한 후 단일 결과를 반환할 수 있습니다. MongoDB는 세 가지 어그리게이션을 제공합니다.
- Aggregation Pipeline
- Single Purpose Aggregation Operations
- Map-reduce
어그리게이션 파이프라인(Aggregation Pipeline)
Aggregation pipeline 은 파이프라인 이용해 데이터의 집계를 처리하는 프레임워크입니다. 여러 스테이지에 걸쳐 도큐먼트들을
집계된 결과로 변경합니다.
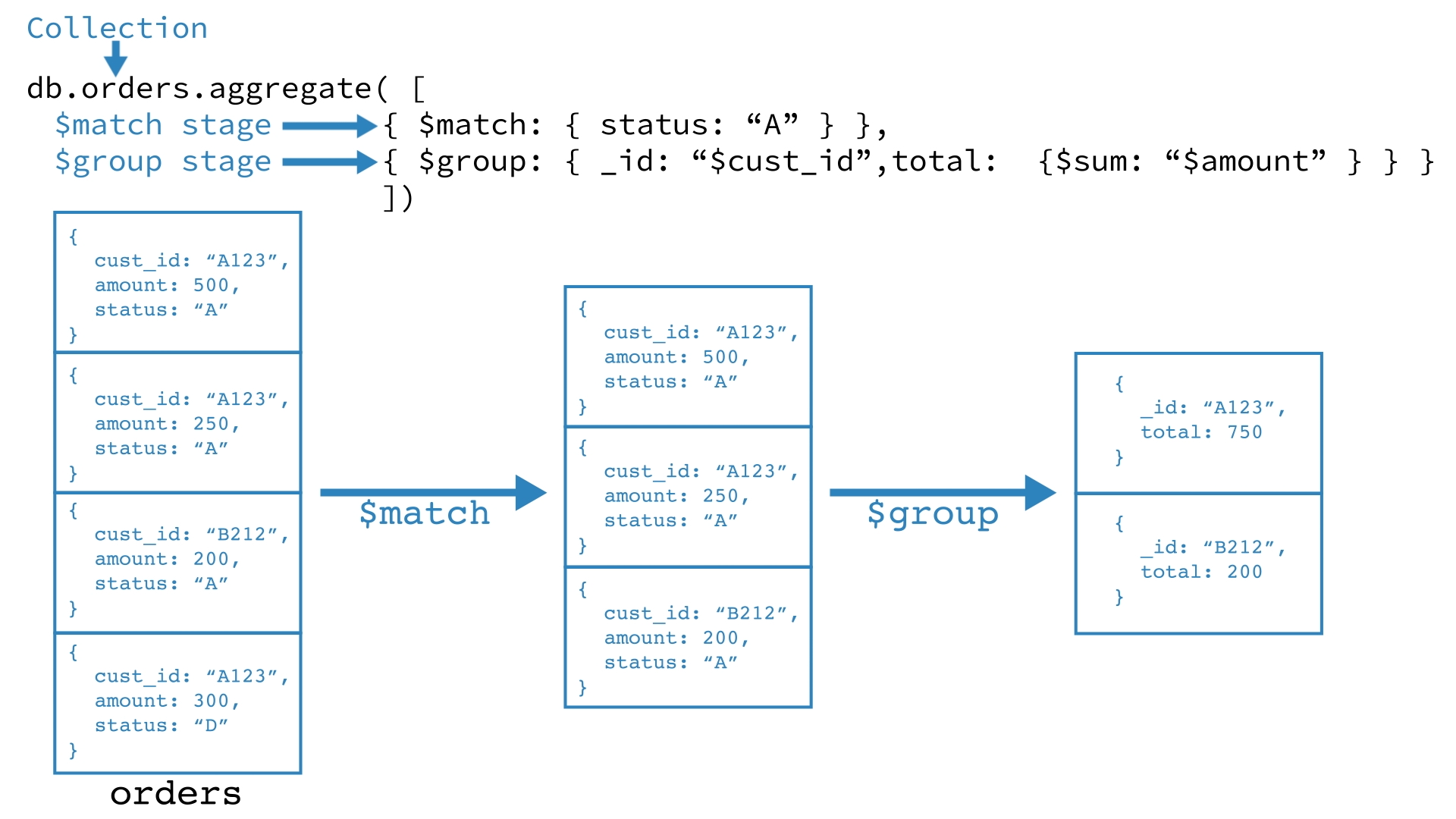
아래 예를 살펴봅시다:
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$custmor_id", total: { $sum: "$amount" } } }
])
쿼리 기준과 일치하는 도큐먼트에 대한 커서를 반환합니다.
파라미터
- query: 필터에 사용할 쿼리 연산자입니다.
- projection: 도큐먼트에서 반환할 필드를 지정합니다. 생략하면 모든 필드가 반환됩니다.
쿼리 기준과 일치하는 하나의 도큐먼트를 반환합니다.
여러 도큐먼트들이 쿼리를 만족하면 디스크에 저장된 순서에 따라 첫 도큐먼트를 반환합니다.
만약 대상이 없으면 null을 반환합니다.
readConcern 옵션을 사용해 읽기 작업의 일관성과 격리수준, 가용성을 제어할 수 있습니다.
4.4 버전부터 기본값의 전역 설정이 가능합니다. 세부정보는 setDefaultRWConcern에서 확인하십시오.
Read Concern Levels
- local
- 과반수에 기록되었음을 확인하지 않고 데이터를 반환합니다.(읽어온 데이터가 롤백될 수 있음)
- 사용가능:
causally consistent session 또는 트랜잭션에서 사용할 수 있습니다.
- available
- 과반수에 기록되었음을 확인하지 않고 데이터를 반환합니다.(읽어온 데이터가 롤백될 수 있음)
- 사용가능:
causally consistent session 또는 트랜잭션에서 사용할 수 없습니다.
- 샤딩된 클러스터에서 가장 낮은 레이턴시를 제공합니다. 하지만 샤드된 컬렉션에서 orphaned document를 반환할 수 있음을 유의하십시오.
- majority
- 과반수에 기록된 데이터를 반환합니다.
- 이를 충족하기 위해 각 레플리카 셋 멤버들이 메모리의
majority-commit point 반환해야 합니다. 따라서 위 두 설정에 비해 성능이 떨어집니다.
- 사용가능:
causally consistent session 또는 트랜잭션에서 사용할 수 있습니다.- PSA 아키텍처를 사용할 때 이 설정을 쓰지 않게 설정할 수 있습니다. 하지만 이것은 Change Streams, 트랜잭션, 샤디드 클러스터에 영향을 줄 수 있습니다. 자세한 내용은 Disable Read Concern Majority에서 확인하십시오.
- linearizable
- 읽기를 시작하기 전에 완료된 쓰기에 대한 데이터만 반환합니다. 쿼리가 결과를 반환하기 전에 레플리카 셋 전체에 결과가 전파되길 기다립니다.
- 읽기 시작 후 레플리카 셋의 과반이 재시작되어도, 반환된 데이터는 유효합니다.(
writeConcernMajorityJournalDefault 을 false 로 변경하면 아닐 수 있음)
- 사용가능:
causally consistent session 또는 트랜잭션에서 사용할 수 없습니다.- 프라이머리 노드에만 설정할 수 있습니다.
- 어그리게이션의 $out, $merge 스테이지에서 사용할 수 없습니다.
- 요구사항: 유니크하게 식별가능한 단일 도큐먼트에 읽기 작업에서만 보장됩니다.
- snapshot
- 트랜잭션이
causally consistent session 이 아니고 Write concern 이 majority 인 경우, 트랜잭션은 과반이 커밋된 데이터의 스냅샷에서 읽습니다.
- 트랜잭션이
causally consistent session 이고 Write concern 이 majority 인 경우, 트랜잭션 시작 직전에 과반이 커밋된 데이터의 스냅샷에서 읽습니다.
- 사용가능:
뭔가 묘한 일관성 옵션입니다. 잘 찾아보면 활용할 만 한 특수한 사용처가 있을지도 모릅니다.
샤딩
샤딩은 여러 물리장비에 데이터를 분산하는 방법
MongoDB 는 샤딩을 이용해 매우 큰 데이터에 대해 높은 처리량을 제공
시스템을 확장하는 두 가지 방법
- 스케일업
- 스케일아웃(MongoDB 는 샤딩 통해 스케일아웃을 지원)
대상이 되는 자원
고려사항
경제적으로 이득인가?
실현가능한가?
예 1)
- 서버의 CPU 자원에 한계가 다가오고 필요한 CPU 자원은 2배로 예상됨
- 다음으로 좋은 CPU는 처리량이 10배이고 비용도 10배임
- 스케일업을 한다면 10배의 비용으로 2배의 CPU만 사용
- 스케일아웃을 한다면 2배의 비용으로 2배의 CPU 사용가능
예 2)
- 현재 사용가능한 가장 좋은 CPU를 사용 중 자원에 한계가 다가옴
- 스케일업으로 해결불가
- 스케일아웃으로 해결가능
예 3)
- 디스크를 1TB 에서 20TB 로 20배 스케일업
- 백업, 복구, resync 에 20배의 시간이 듬
- 스케일아웃한다면 병렬화의 장점을 사용해 시간을 절약할 수 있음
- 또 MongoDB의 경우 큰 데이터는 큰 인덱스를 만들기 때문에 메모리 사용량도 함께 증가함
기타 장점
분산처리에 용이하기 때문에 MongoDB 에서 제공하는 존 샤딩, 어그리게이션 등의 기능을 효과적으로 사용가능
Replica Set
Replica set 은 같은 데이터를 가진 mongod 프로세스 그룹입니다. 이를 통해 MongoDB는 데이터 중복과 고가용성을 제공합니다. 그렇기 때문에 일부 서버에 장애가 발생하더라고 전체 시스템은 정상적으로 운영될 수 있습니다.
특정한 경우 복제를 통해 읽기 수용량을 증가시킬 수 있습니다. 또 서로 다른 데이터센터에 복사본을 유지하여 가용성을 증가시킬수 있도 장애복구, 분석, 백업 목적으로 추가 복사본을 만들 수도 있습니다.
Replication
Replica set 은 데이터를 가진 여러 노드로 이루어지며(데이터가 없는 아비터가 추가될 수도 있음), 이 중 하나만이 primary 노드가 됩니다.
들어가며
지금까지 필요 없는 로그성 데이터를 MongoDB에 저장한 경험이 있으며, 대부분은 RDBMS를 사용했습니다. MongoDB도 많이 발전하였고(트랜잭션, 컨시스턴시 관련) 우리의 MongoDB 운영능력도 증가했기 떄문에 애플리케이션에서 스케일아웃을 핸들링하지 않고 MongoDB를 사용해 개발속도를 향상시키고 싶습니다.
MongoDB란
도큐먼트를 기본 자료형으로 사용하는 NoSQL 데이터베이스
도큐먼트와 컬렉션
- 도큐먼트
- 도큐먼트는 field와 value의 쌍으로 데이터를 저장하고 관리
- JSON 형태로 사용되며 실제로는 BSON으로 시리얼라이즈되어 저장됨
{
"name" : "hueypark",
"title" : "software engineer"
}
- 컬렉션
- 도큐먼트들이 모여있는 집합
- 일반적으로 한 컬렉션에 있는 도큐먼트들은 공통된 필드를 가지고 있음
BSON
BSON은 바이너리로 시리얼라이즈 된 JSON