MongoDB 스터디 8주차(aggregation)
어그리게이션(Aggregation)
어그리게이션 작업은 데이터를 처리하여 계산된 결과를 반환합니다. 어그리게이션은 여러 도큐먼트의 값을 그룹화하고, 데이터에 다양한 작업을 수행한 후 단일 결과를 반환할 수 있습니다. MongoDB는 세 가지 어그리게이션을 제공합니다.
- Aggregation Pipeline
- Single Purpose Aggregation Operations
- Map-reduce
어그리게이션 파이프라인(Aggregation Pipeline)
Aggregation pipeline 은 파이프라인 이용해 데이터의 집계를 처리하는 프레임워크입니다. 여러 스테이지에 걸쳐 도큐먼트들을 집계된 결과로 변경합니다.
아래 예를 살펴봅시다:
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$custmor_id", total: { $sum: "$amount" } } }
])
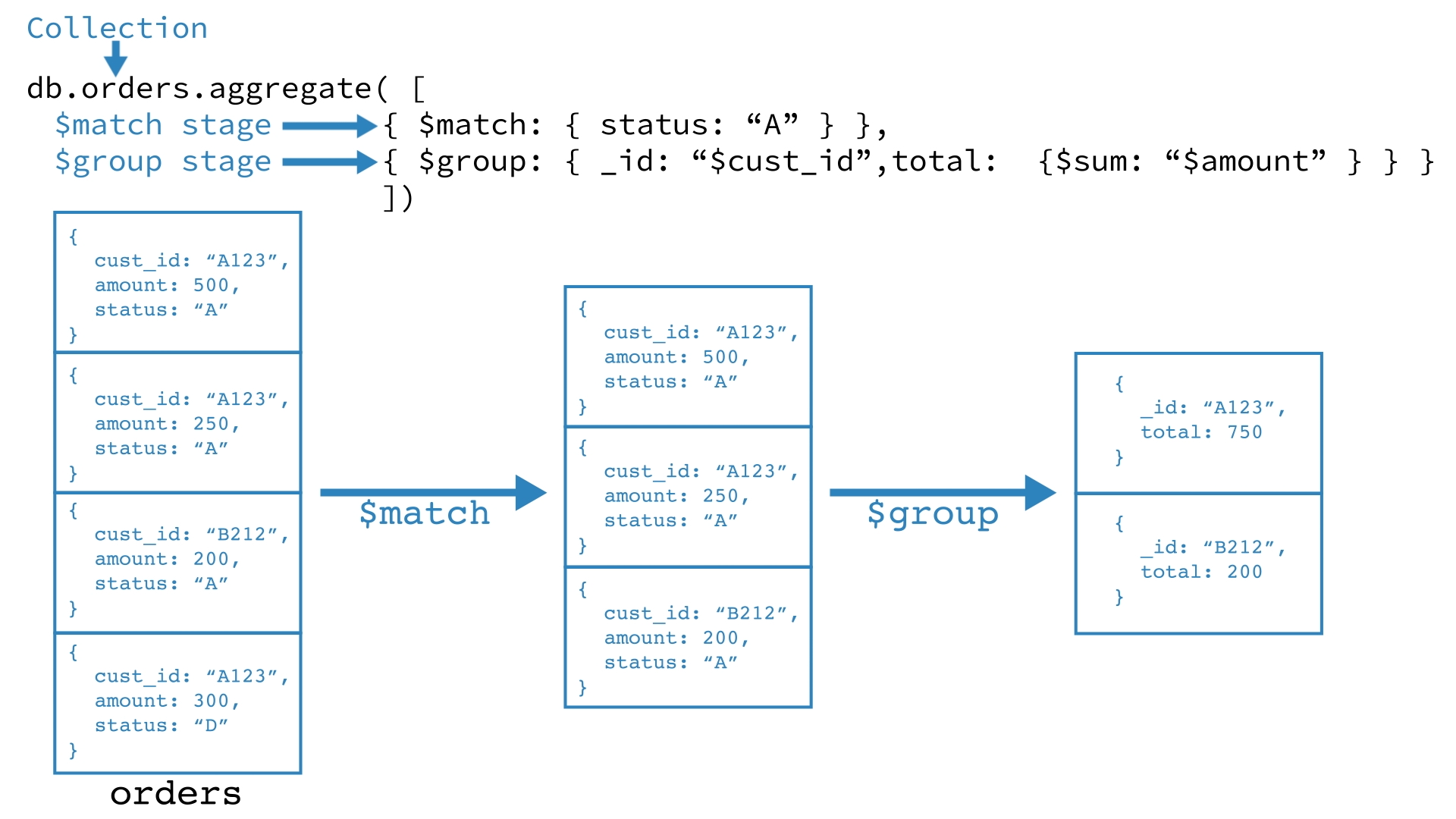
- $match 스테이지는 도큐먼트들을
status필드가"A"인 데이터만 다음 스테이지로 보냅니다. - $group 스테이지는
custmor_id로 도큐먼트를 그룹화 한 다음$amount의 합을 계산합니다.
파이프라인
파이프라인은 스테이지들로 구성됩니다. 각 스테이지는 도큐먼트들 처리해 변환합니다. 스테이지는 하나의 입력된 도큐먼트보다 많거나 적은 도큐먼트를 반환 할 수도 있습니다. 예를 들어 새 문서를 생성하거나 기존 문서를 필터링 할 수 있습니다.
$out, $merge, $geoNear 를 제외한 스테이지는 파이프라인에 여러 번 사용될 수 있습니다.
고려사항
어그리게이션 파이프라인 제약사항
- 결과 크기 제한
- 반환되는 도큐먼트 크기는 16 메가바이트로 제한됩니다
- 이 제한은 마지막으로 반환되는 도큐먼트에만 적용되고, 파이프라인 안에서는 더 클 수 있습니다.
- 메모리 제한
- 스테이지는 100 메가바이트 이상의 메모리를 쓸 수 없습니다.
- 그보다 큰 데이터를 처리하려면
allowDiskUse옵션을 사용해 데이터를 임시 파일에 쓸 수 있습니다.
어그리게이션 파이프라인 최적화
최적화 단계를 거쳐 성능이 향상됩니다. explain 최적화된 결과를 볼 수 있습니다.
프로젝션 최적화:
결과를 얻기 위해 도큐먼트의 일부 필드만 필요하다면, 나머지 필드를 제외하여 파이프라인을 통과하는 데이터 양을 줄입니다.
파이프라인 시퀀스 최적화:
($project or $unset or $addFields or $set) + $match 시퀀스 최적화
전:
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: {
name: "Joe Schmoe",
maxTime: { $lt: 20 },
minTime: { $gt: 5 },
avgTime: { $gt: 7 }
} }
후:
{ $match: { name: "Joe Schmoe" } },
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: { avgTime: { $gt: 7 } } }
$sort + $match 시퀀스 최적화
전:
{ $sort: { age : -1 } },
{ $match: { status: 'A' } }
후:
{ $match: { status: 'A' } },
{ $sort: { age : -1 } }
$redact + $match 시퀀스 최적화
전:
{ $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } },
{ $match: { year: 2014, category: { $ne: "Z" } } }
후:
{ $match: { year: 2014 } },
{ $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } },
{ $match: { year: 2014, category: { $ne: "Z" } } }
$project/$unset + $skip 시퀀스 최적화
전:
{ $sort: { age : -1 } },
{ $project: { status: 1, name: 1 } },
{ $skip: 5 }
후:
{ $sort: { age : -1 } },
{ $skip: 5 },
{ $project: { status: 1, name: 1 } }
파이프라인 병합(Coalescence) 최적화
$sort + $limit 병합
전:
{ $sort : { age : -1 } },
{ $project : { age : 1, status : 1, name : 1 } },
{ $limit: 5 }
후:
{
"$sort" : {
"sortKey" : {
"age" : -1
},
"limit" : NumberLong(5)
}
},
{ "$project" : {
"age" : 1,
"status" : 1,
"name" : 1
}
}
$limit + $limit 병합
전:
{ $limit: 100 },
{ $limit: 10 }
후:
{ $limit: 10 }
$skip + $skip 병합
전:
{ $skip: 5 },
{ $skip: 2 }
후:
{ $skip: 7 }
$match + $match 병합
{ $match: { year: 2014 } },
{ $match: { status: "A" } }
{ $match: { $and: [ { "year" : 2014 }, { "status" : "A" } ] } }
$lookup + $unwind 병합
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y"
}
},
{ $unwind: "$resultingArray"}
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y",
unwinding: { preserveNullAndEmptyArrays: false }
}
}
$sort + $skip + $limit 시퀀스
{ $sort: { age : -1 } },
{ $skip: 10 },
{ $limit: 5 }
{
"$sort" : {
"sortKey" : {
"age" : -1
},
"limit" : NumberLong(15)
}
},
{
"$skip" : NumberLong(10)
}
샤딩된 컬렉션에 대한 어그리게이션
동작방식
만약 파이프라인이 샤드 키로 구분 가능한 $match 로 시작하면 해당 샤드에서만 파이프라인이 실행됩니다.
작업이 여러 샤드에서 실행되면 결과는 mongos 로 라우팅 되어 합쳐집니다.(아래 경우를 제외하고)
- 파이프라인이
$out또는$lookup스테이지를 가지고 있으면 프라이머리 샤드에서 머지됩니다. - 파이프라인이 sort 또는 grouping 스테이지를 가지고 있고, allowDiskUse 설정이 켜저 있으면 머지는 임의로 선택된 샤드에서 실행됩니다.
최적화
파이프라인을 두 파트로 나눌 수 있다면, 가능한 한 많은 단계로 나누어 실행되게 최적화합니다.
예: 우편번호 데이터 어그리게이션
데이터 모델
{
"_id": "10280", // 우편번호
"city": "NEW YORK", // 도시
"state": "NY", // 주(약자)
"pop": 5574, // 인구
"loc": [ // 위치(위경도 좌표)
-74.016323,
40.710537
]
}
천만 명 이상의 인구가 있는 주 반환
db.zipcodes.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gte: 10*1000*1000 } } }
] )
결과
{
"_id" : "AK",
"totalPop" : 550043
}
주 내 도시의 평균 인구 반환
db.zipcodes.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$pop" } } }
] )
결과
{
"_id" : "MN",
"avgCityPop" : 5335
}
주 내 가장 큰 도시와 가장 작은 도시 반환
db.zipcodes.aggregate( [
{ $group:
{
_id: { state: "$state", city: "$city" },
pop: { $sum: "$pop" }
}
},
{ $sort: { pop: 1 } },
{ $group:
{
_id : "$_id.state",
biggestCity: { $last: "$_id.city" },
biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.city" },
smallestPop: { $first: "$pop" }
}
},
// the following $project is optional, and
// modifies the output format.
{ $project:
{ _id: 0,
state: "$_id",
biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" }
}
}
] )
결과
{
"state" : "RI",
"biggestCity" : {
"name" : "CRANSTON",
"pop" : 176404
},
"smallestCity" : {
"name" : "CLAYVILLE",
"pop" : 45
}
}