(번역) 카크로치디비(CockroachDB) 블로그 / 고가용성의 역사
원문: https://www.cockroachlabs.com/blog/brief-history-high-availability/
Written by Sean Loiselle on Oct 4, 2018

저는 “영업시간"이 있는 웹사이트에 방문한 적이 있습니다. 이 웹사이트는 오프라인 버전이 영업 중인 경우에만 “열려” 있었습니다. 저는 당황하고 실망했습니다. 컴퓨터는 온종일 운영될 수 있는데 왜 그러지 않았을까요? 저는 인터넷의 놀라운 가용성 보장에 익숙했습니다.
하지만, 인터넷이 나오기 전에 하루 24시간 주 7일의 가용성은 “기본"이 아니었습니다. 가용성은 필요했지만, 기본으로 생각되지 않았습니다. 우리는 필요할 때만 컴퓨터를 사용했고 사용량이 없을 때 유지시키지 않았습니다. 인터넷이 성장함에 따라 새벽 3시의 흔하지 않은 요청이 전 세계의 주요 업무시간이 되었고, 그것을 처리하는 것이 중요해졌습니다.
많은 시스템은 이러한 요청을 위해 단 하나의 컴퓨터에 의존했습니다. 우리가 모두 잘 알듯이 이런 경우는 좋게 끝나지 않았습니다. 서비스를 계속 유지하기 위해 우리는 요구사항을 충족할 수 있는 여러 대의 컴퓨터에 부하를 분산시켜야 했습니다. 그러나 분산 처리는 장점과 함께 날카로운 특징을 가집니다. 대표적으로 동기화와 부분결함허용을 요구합니다. 각 세대의 엔지니어는 시대의 요구에 따라 이러한 솔루션을 개발해 왔습니다.
데이터베이스에 대한 분산처리 도입과정은 흥미로운데, 컴퓨터 사이언스의 다른 영역보다 개발이 훨씬 느린 어려운 문제이기 때문입니다. 물론 소프트웨어는 로컬 데이터베이스에서 일부 분산 계산을 하게 되었지만, 데이터베이스의 상태는 단일 시스템에 저장되었습니다. 왜냐고요? 여러 머신에서 상태를 복제하는 것이 어렵기 때문입니다.
이 글에서 분산 데이터베이스가 시스템 내에서 부분적인 실패를 처리한 방법의 역사에 대해 살펴보고, 고가용성이 무엇인지 알아보겠습니다.
가지고 있는 것의 활용: 액티브-패시브
예전에는 데이터베이스가 단일 머신에서 실행되었습니다. 하나의 노드만 있었고 그것이 모든 읽기와 쓰기를 처리했습니다. “부분적인 실패” 같은 것은 존재하지 않았고, 데이터베이스는 동작하거나 멈춰있었습니다.
단일 데이터베이스의 실패는 인터넷에 두 가지 문제였습니다. 첫째, 컴퓨터가 24시간 내내 접근 중이었기 때문에 가동중지 시간이 사용자에게 직접적인 영향을 줄 수 있었습니다. 둘째, 컴퓨터를 일정한 수요에 따라 배치했기 때문에 실패 가능성이 컸습니다. 이 문제를 해결할 수 있는 확실한 방법은 요청을 처리할 수 있는 컴퓨터가 두 대 이상 있는 것입니다. 여기서 분산 데이터베이스에 대한 이야기가 진짜 시작됩니다.
단일 노드 환경에서 가장 자연스러운 솔루션은 단일 노드가 읽기 및 쓰기 기능을 제공하게 하고 계속해서 보조 패시브 시스템에 동기화 하는 것이었습니다. 따라서 액티브-패시브 복제가 탄생했습니다.
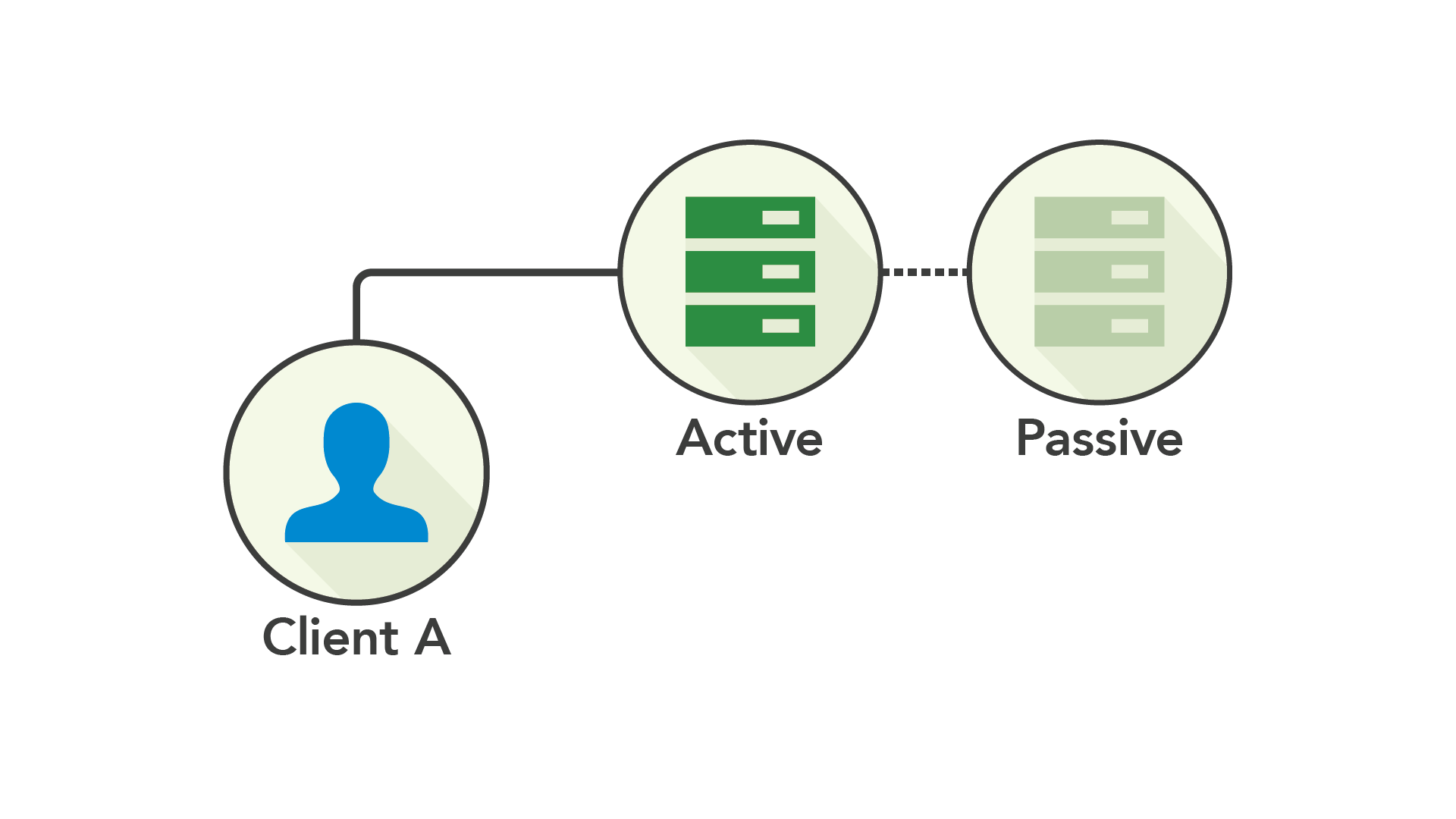
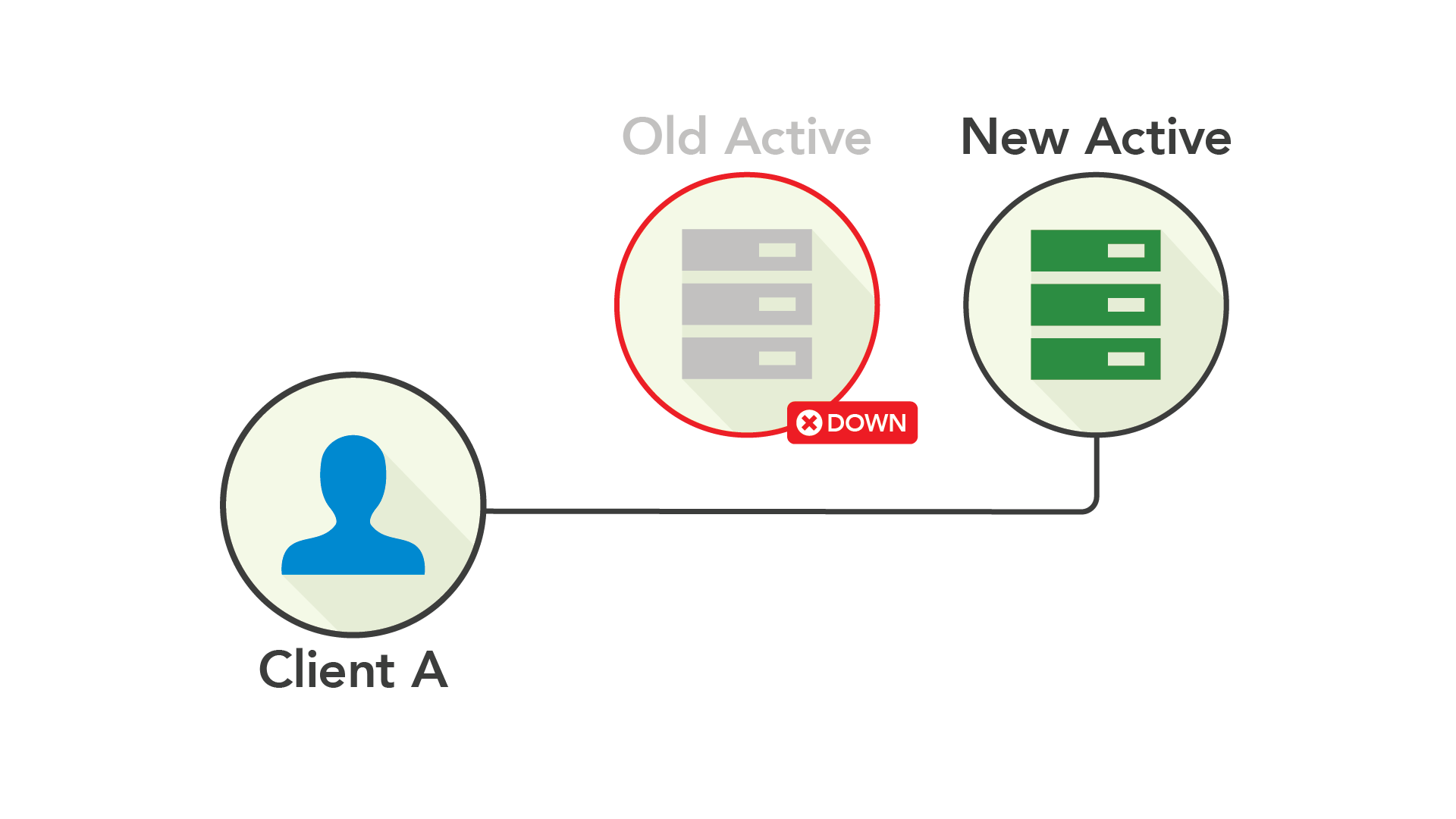
액티브-패시브는 액티브 노드가 실패한 경우 최신 백업을 유지함으로써 가용성을 향상했습니다. 패시브 노드를 액티브로 승급시켜 트래픽을 옮기기만 하면 됩니다. 가능하다면 다운된 서버를 새로운 패시브 시스템으로 교체합니다(잠깐 액티브 노드가 실패하지 않길 바랍니다).
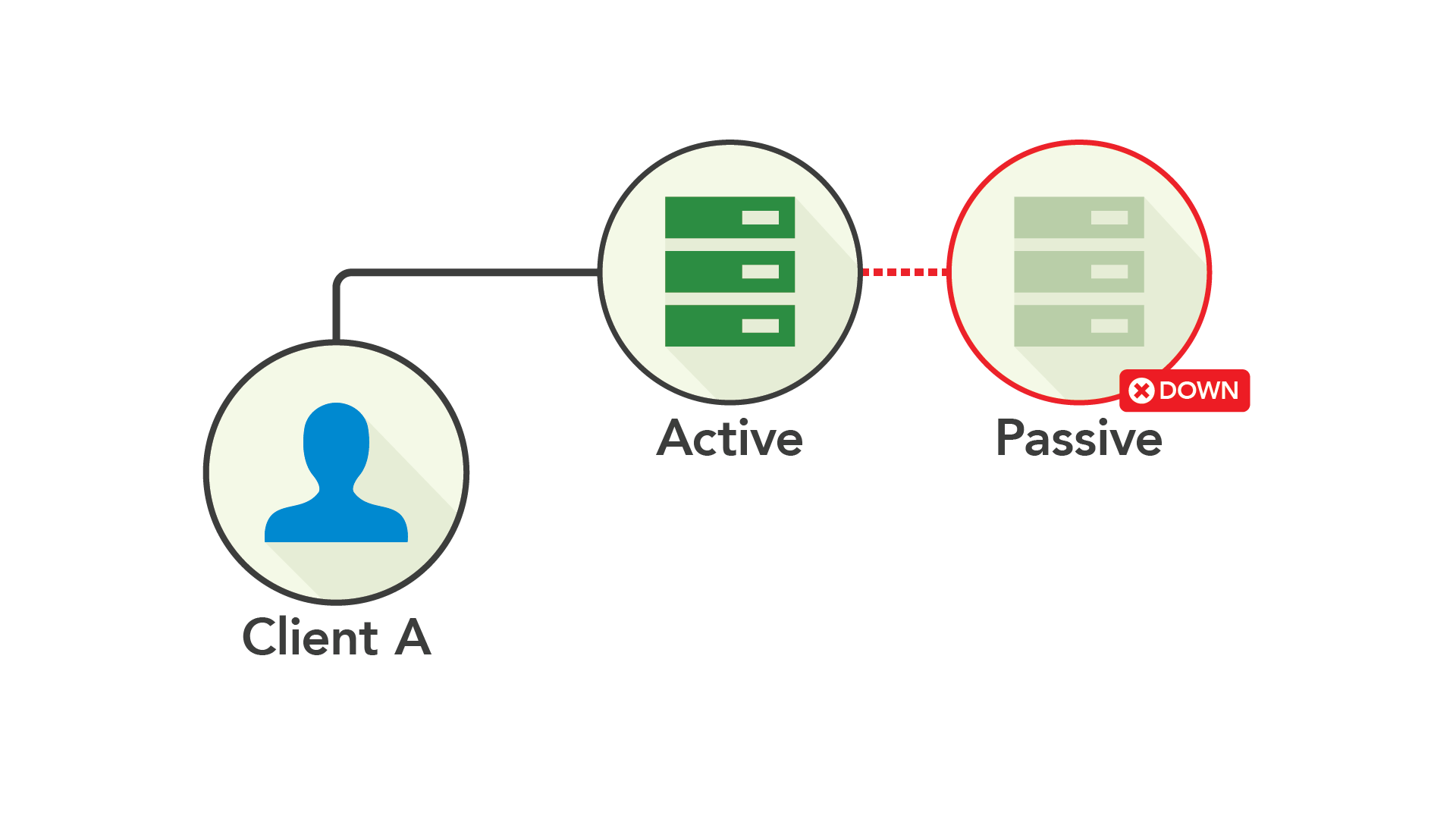
처음에는 액티브에서 패시브 노드로의 복제가 동기식이었습니다. 즉, 패시브 노드가 승인할 때까지 변경이 커밋되지 않았습니다. 하지만 이 경우 패시브 노드가 다운되었을 경우의 동작이 불명확합니다. 백업 시스템이 가용하지 않다고 해서 전체 시스템이 다운되는 것은 이상하지만 동기화 복제에서 일어날 수 있습니다.
가용성을 더욱 향상하려면 데이터를 비동기적으로 복제할 수 있습니다. 아키텍처는 같아 보이지만 데이터베이스의 가용성에 영향을 주지 않고 액티브 및 패시브 노드를 처리할 수 있습니다.
비동기 액티브-패시브는 한 단계 발전했지만, 여전히 치명적인 단점이 있습니다.
- 액티브 노드가 죽으면 패시브 노드에 아직 복제되지 않은 데이터는 손실됩니다. 클라이언트는 완전히 커밋되었다고 믿을 수 있습니다.
- 트래픽을 처리하기 위해 단일 시스템을 사용하기 때문에 단일 머신의 최대 사용 가능 자원에 여전히 의존적입니다.
99.999%를 향하여: 여러 장비로 스케일하기
인터넷이 퍼짐에 따라 비즈니스 요구사항에 규모와 복잡성이 커졌습니다. 데이터베이스의 경우 이것은 단일 노드가 처리할 수 있는 것보다 많은 트래픽을 처리할 수 있어야 하고, “항상 켜진” 고가용성을 제공하는 것이 필수사항이라는 의미였습니다.
분산 기술에 대한 경험이 엔지니어들에게 생겼으므로, 액티브-패시브를 뛰어넘어 데이터베이스를 여러 머신에 분산할 수 있는 것은 분명했습니다.
샤딩
현재 가지고 있는 것을 사용하여 쉽게 시작할 수 있으므로, 액티브-패시브 복제에 샤딩을 도입해 확장성을 부여했습니다.
이 방법에서는 클러스터의 데이터를 일정 값(행의 수, 기본 키의 유니크 값 등)을 이용해 구분하여 액티브-패시브 쌍이 있는 여러 구역으로 분산시킵니다. 그런 다음 클러스터 앞에 일종의 라우팅 기술을 추가하여 클라이언트가 요청에 맞는 사이트로 이동하도록 합니다.
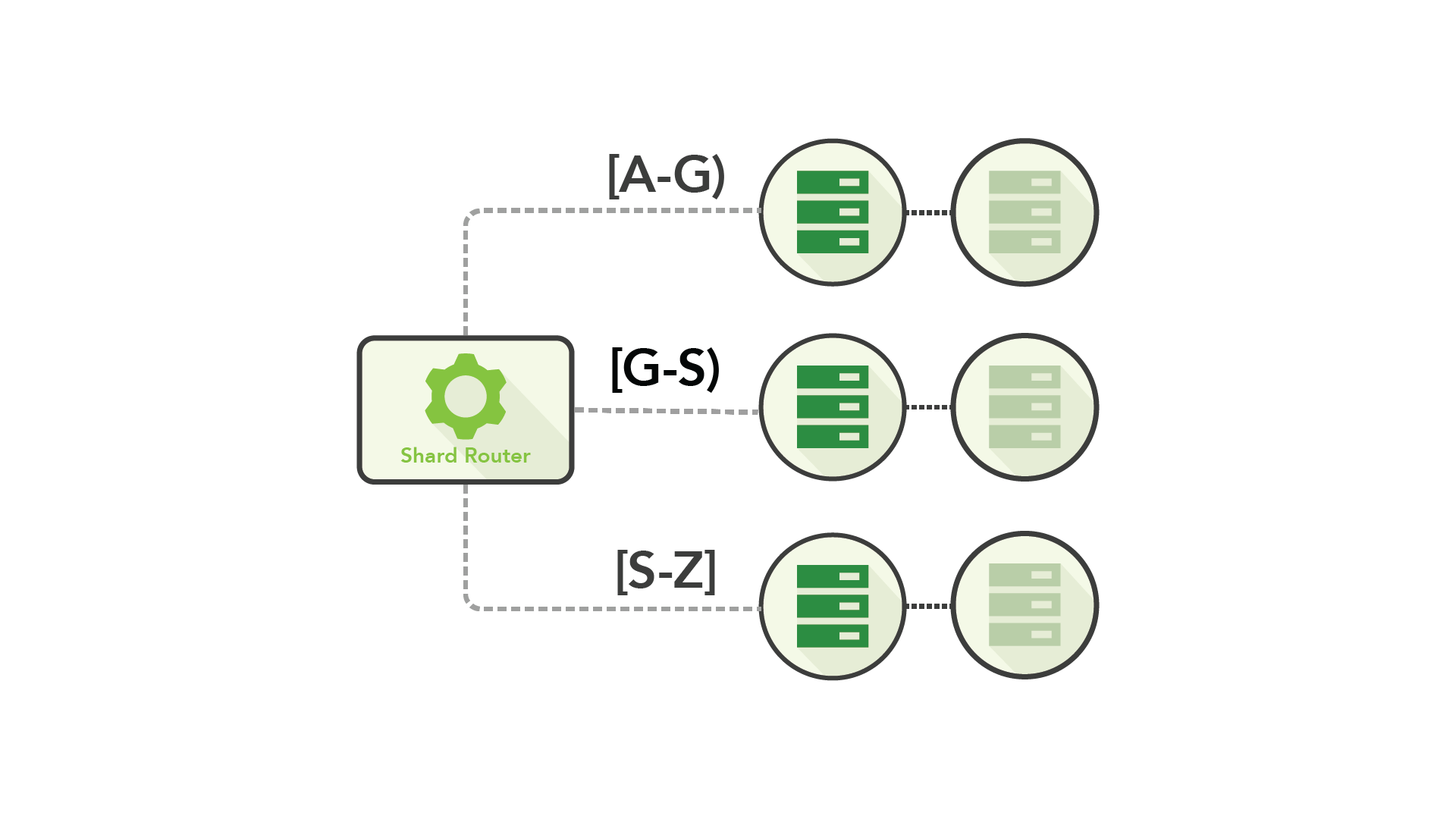
샤딩을 사용하면 많은 컴퓨터에 작업부하를 분산하여 처리량을 향상할 수 있을 뿐 아니라, 더 많은 부분 오류를 허용하여 큰 장애내성을 가질 수 있습니다.
이런 장접에도 불구하고 시스템을 샤딩하는 것은 복잡했으며 팀에 상당한 운영부담을 안겨주었습니다. 샤드의 계산은 무거워져 결국 애플리케이션의 비즈니스 로직으로 들어왔습니다. 그리고 샤딩이 되는 방식을 변경(스키마 변경 등)하기 위해서는 상당량의(때때로 터무니없는) 엔지니어링 비용을 지급해야 했습니다.
단일 노드 액티브-패시브 시스템은 트랜잭션을 제공했습니다(강력한 일관성이 아니더라도). 그러나 샤드들에서 트랜잭션을 처리하는 데 따른 어려움은 너무 복잡하여, 많은 샤드 된 시스템이 이를 완전히 배제하기로 했습니다.
액티브-액티브
샤드 된 데이터베이스는 관리하기 어렵고 완벽히 기능하지 못했기 때문에 엔지니어들은 적어도 하나의 문제를 해결할 시스템을 개발하기 시작했습니다. 여전히 트랜잭션을 지원하지 않지만, 관리가 훨씬 쉬워진 시스템이 등장했습니다. 애플리케이션의 가동시간에 대한 요구가 증가함에 따라 팀이 SLA를 충족하게 하는 것은 현명한 결정이었습니다.
이러한 시스템은 각 사이트가 클러스터 데이터 중 일부(또는 전부)를 포함하고 클러스터 데이터를 읽고 쓰는 역할을 할 수 있습니다. 노드가 쓰기를 수신하면 변경사항의 사본을 필요로 하는 다른 모든 노드에 전파합니다. 두 노드가 동일한 키에 대한 쓰기를 수신한 상황을 처리하기 위해 커밋하기 전, 충돌 해결 알고리즘으로 다른 노드의 변환을 처리하였습니다. 각 사이트가 “액티브” 상태이므로 액티브-액티브라고 불립니다.
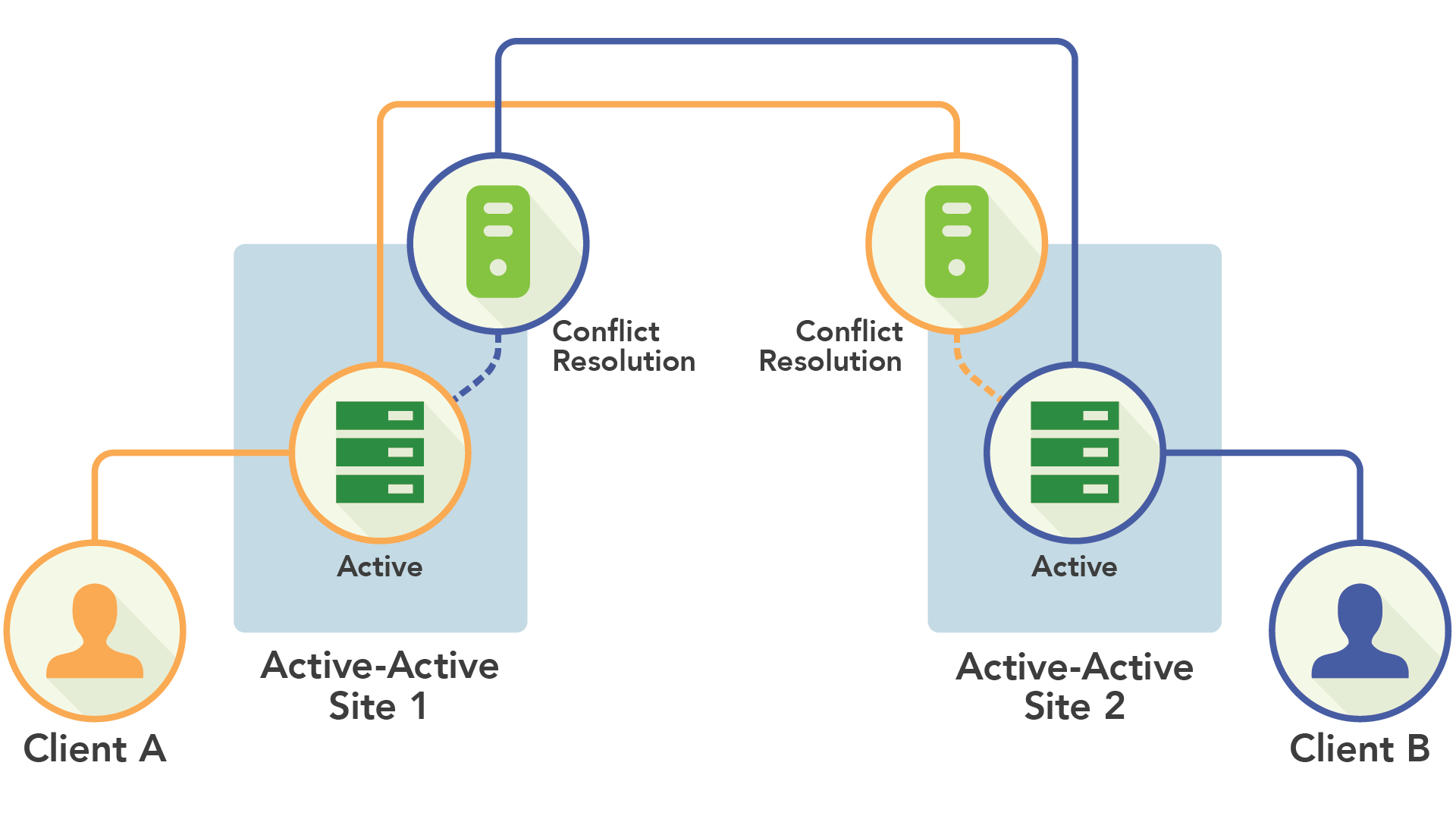
각 서버는 모든 데이터에 대해 읽기 및 쓰기를 처리할 수 있으므로 샤딩을 알고리즘을 이용해 해결하기 쉬워졌으며 배포를 쉽게 관리할 수 있었습니다.
가용성 면에서 액티브-액티브는 뛰어났습니다. 노드에 장애가 발생하면 클라이언트는 데이터가 포함된 다른 노드로 리디렉션됩니다. 하나의 레플리카만 살아있으면, 읽기와 쓰기를 모두 수행할 수 있습니다.
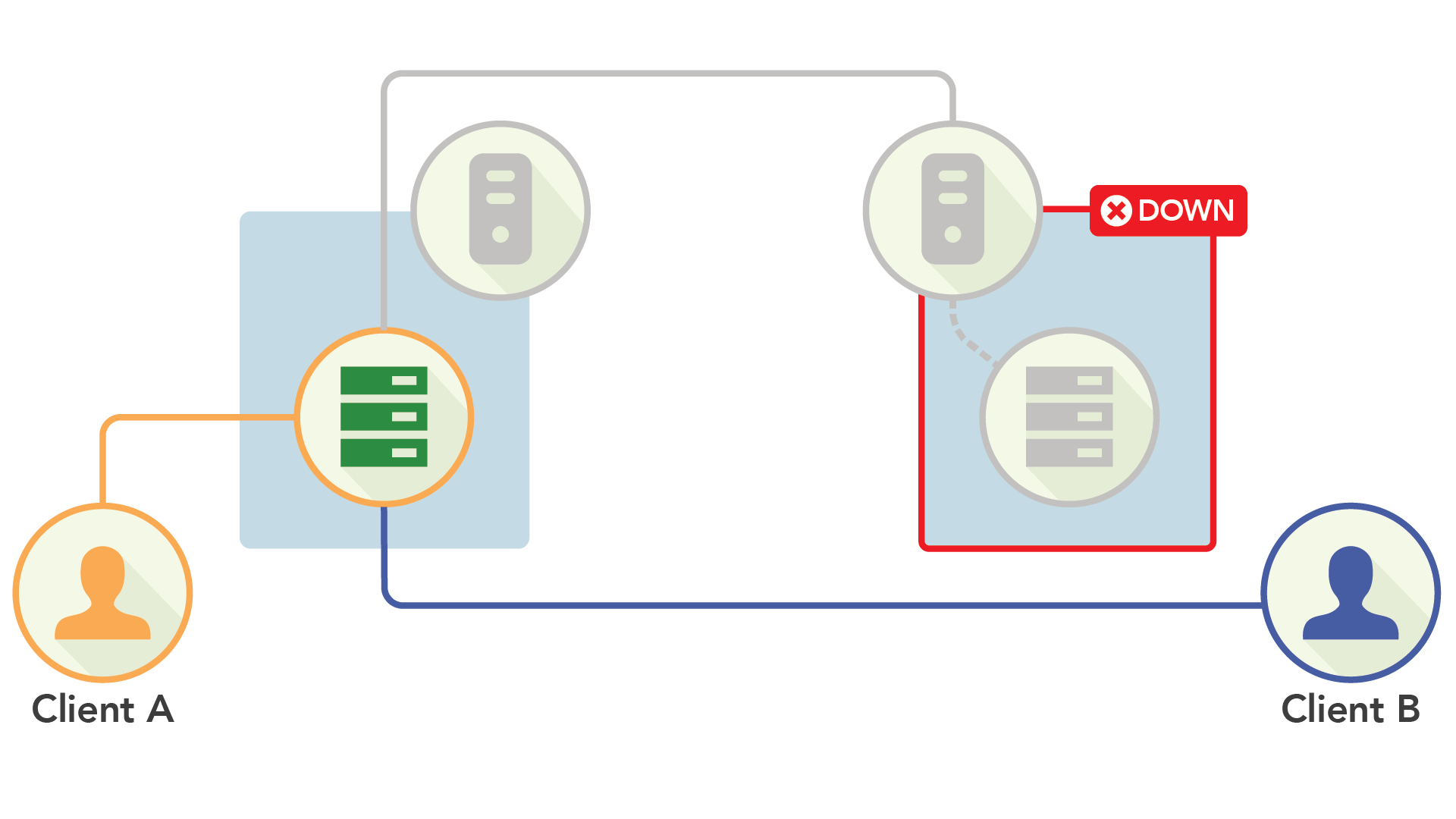
이 방법의 가용성은 환상적이지만, 근본적으로 일관성과는 다른 디자인입니다. 각 사이트가 키 쓰기(와 장애처리)를 처리할 수 있기 때문에 처리 중인 데이터를 완전히 동기화하는 것은 매우 어렵기 때문입니다. 대신 충돌 해결 알고리즘을 통해 사이트 간의 충돌을 조정하여 불일치를 “원할하게” 처리하는 거친 방법을 사용합니다.
클라이언트가 처리에 대한 응답을 이미 받은 후 해결작업이 후처리 되고, 클라이언트가 응답을 기반으로 비즈니스 로직을 실행했기 때문에, 액티브-액티브 복제에서는 데이터 이상현상이 쉽게 생깁니다.
대규모에서 일관성: 합의 및 멀티-액티브 가용성
액티브-액티브는 인프라가 직면한 주요 문제(가용성)를 해결한 것 같았지만, 강력한 일관성이 필요한 시스템을 고려하지 않았습니다.
예를 들어 구글은 광고 비즈니스를 위해 복잡하게 샤드 된 MySQL 시스템을 사용했습니다. 이 시스템은 SQL의 표현력에 의존하여 데이터베이스를 임의로 쿼리합니다. 이러한 쿼리는 성능향상을 위해 보조 인덱스에 의존해야 하므로 파생된 데이터와 완전히 일치해야 했습니다.
결국 시스템은 크기가 커져 샤드 된 MySQL에 문제가 생기기 시작했습니다. 따라서 엔지니어들은 대규모로 확장 가능함과 동시에 비즈니스가 요구하는 강력한 일관성을 제공하는 시스템을 생각하기 시작했습니다. 액티브-액티브의 트랜잭션 지원 부족은 옵션이 될 수 없으므로 새로운 것을 설계해야 했습니다. 결국 그들은 일관성을 보장하는 합의 복제를 기반으로 한 시스템이 구축했는데, 일관성을 보장하며 동시에 높은 가용성을 제공했습니다.
합의 복제를 사용하여 쓰기가 노드에 제안된 다음 다른 노드들에 복제됩니다. 대부분의 노드가 쓰기를 확인하면 커밋될 수 있습니다.
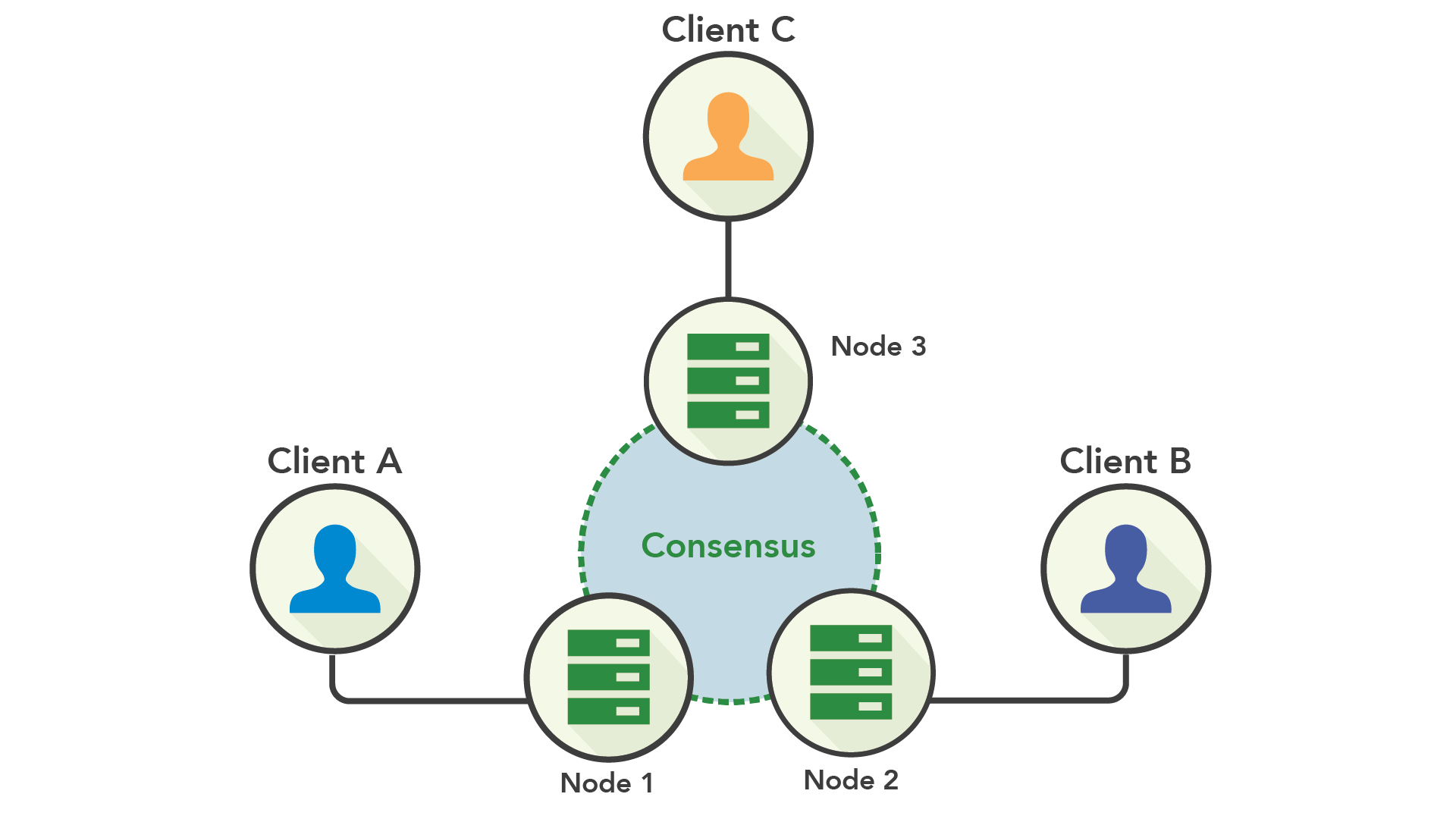
합의와 고가용성
여기서 핵심 개념은 합의 복제가 동기와 비동기식 복제 사이의 적절한 위치에 있다는 것입니다. 당신은 임의의 몇 개 노드가 동기적으로 동작하는 것을 필요로 하지만 어떤 노드인지는 중요하지 않습니다. 이것은 클러스터가 시스템의 가용성에 영향을 주지 않고 소수의 노드가 다운되는 것을 허용한는 것을 의미합니다.
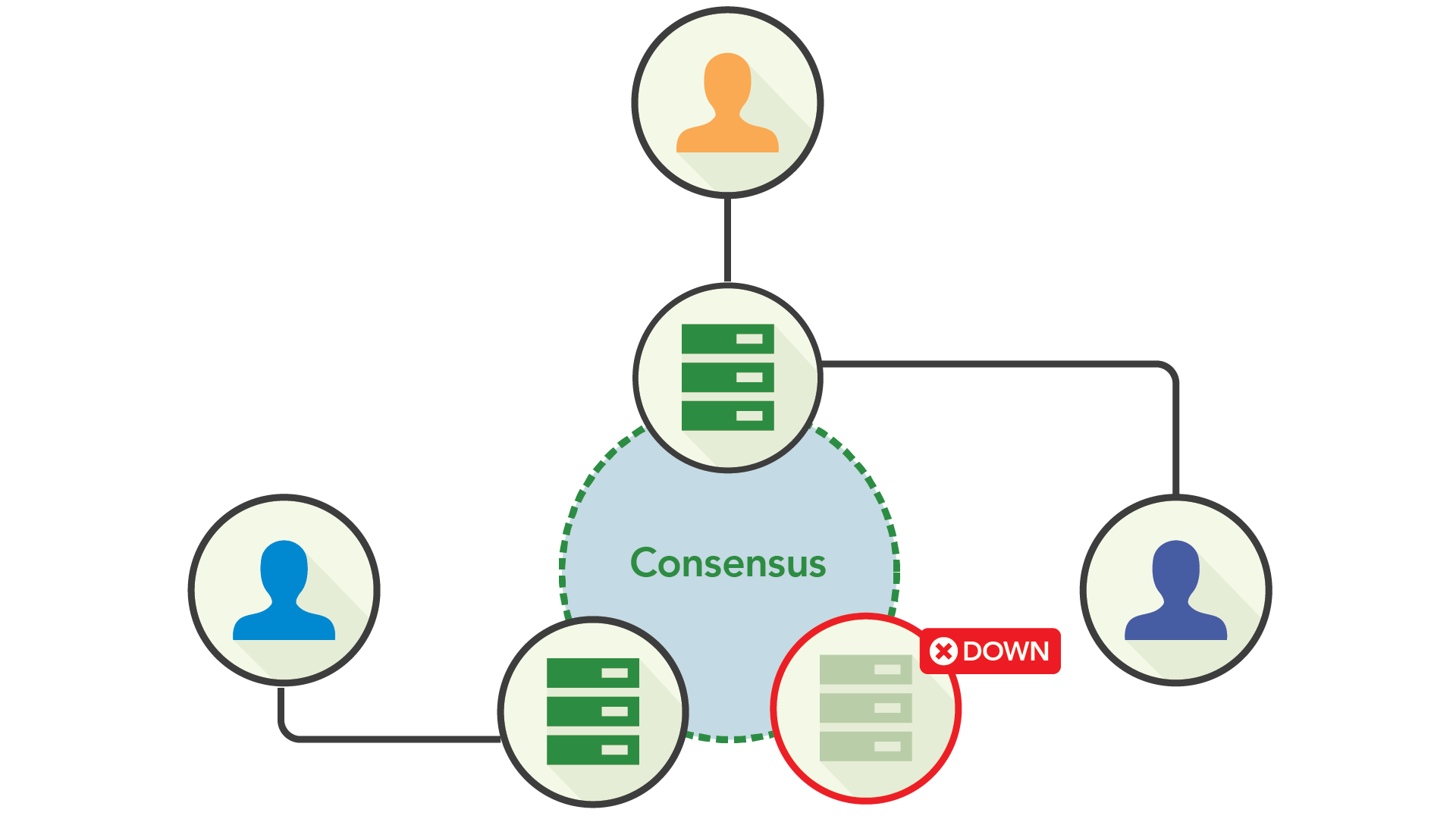
합의를 위해서 노드가 쓰기를 수행할 때 다른 노드와 통신하는 비용이 필요합니다. 노드 간에 발생하는 대기 시간을 줄이기 위해 같은 가용성 영역에 배치하는 것과 같은 작업을 할 수 있지만 가용성은 절충됩니다. 예를 들어 모든 노드가 동일 데이터센터에 있으면 통신이 빠르지만, 데이터센터가 중단되었을 때 살아남을 수 없습니다. 노드를 여러 데이터센터에 분산시키면 쓰기에 필요한 대기시간이 늘어나지만, 애플리케이션을 중단하지 않고 데이터센터를 중단시킬 수 있으므로 가용성이 향상됩니다.
멀티-액티브 가용성
CockroachDB는 합의 복제를 포함해 구글 스패너 문서에서 얻은 많은 내용을 구현(아토믹 시계 없이)하여, 가용성을 훨씬 단순하게 만들었습니다. 이 작동방식을 설명하고 액티브-액티브와 차별화하기 위해 멀티-액티브 가용성이라는 용어를 사용합니다.
액티브-액티브 vs. 멀티-액티브
액티브-액티브는 클러스터의 모든 노드가 키에 대한 읽기 및 쓰기를 제공하도록 허용하며, 쓰기를 수행한 후 다른 노드로 수락한 변경사항을 전파합니다.
멀티-액티브 가용성에서도 모든 노드가 읽기 및 쓰기를 수행할 수 있지만, 대부분의 복제본은 쓰기에서 동기화되고 최신버전의 복제본에서만 읽기를 제공합니다.
가용성 면에서 볼 때 액티브-액티브는 쓰기 작업을 모두 처리할 수 있는 단일 레플리카만 요구하며, 멀티-액티브는 컨셉을 달성하기 위해 대부분의 복제본을 온라인 상태로 유지해야 합니다(시스템 내에서 부분적인 장애가 발생할 수 있음).
그러나 이런 데이터베이스 가용성의 아래에는 일관성의 차이가 있습니다. 액티브-액티브 데이터베이스는 대부분 상황에서 쓰기를 허용하기 위해 클라이언트가 현재와 미래에 같은 데이터를 읽을 수 있는 능력을 보장하지 않습니다. 반면, 멀티-액티브 데이터베이스는 일관성 있는 방식으로 데이터를 읽을 수 있다고 보장할 수 있는 경우에만 쓰기를 허용합니다.
어제, 오늘 그리고 내일
지난 30년간, 데이터베이스 복제 및 가용성은 큰 진보를 이루었으면 이제는 절대 다운되지 않는 느낌을 주는 전 세계 배포를 지원합니다. 첫 번째 과정은 액티브-패시브 복제를 통해 중요한 토대를 만들었지만 결국 더 나은 가용성과 더 큰 규모가 필요했습니다.
우리는 데이터베이스의 두 가지 주요 패러다임을 개발했습니다. 쓰기를 신속하게 수락하는 것이 가장 중요한 애플리케이션의 경우 액티브-액티브이고 일관성이 필요한 애플리케이션의 경우 멀티-액티브입니다.
우리는 양자얽힘을 활용해 분상 상태를 관리하는 다음 패러다임으로 이동할 날을 고대합니다.
Illustration by Christina Chung