(번역) Go 스케줄링 파트 3
원문: https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
프렐류드
Go 스케줄러의 구조와 의미 이해를 제공하는 3부작의 세 번째 글입니다. 이 글은 동시성에 중점을 둡니다.
세 시리즈의 인덱스:
서론
저는 문제를 해결할 때, 특히 그 문제가 새로운 것일 경우 처음에는 동시성이 적합한지 아닌지에 대해 고려하지 않습니다. 먼저 순차적인 해결책을 찾아 작동하는지 확인하고, 다음 가독성과 기술검토를 거쳐 동시성이 합리적이고 실용적인지 질문합니다. 이 때 동시성이 적합한지 아닌지가 명확하게 드러납니다.
이 시리즈의 첫번째 파트에서, 멀티쓰레드 코드를 작성에 중요한 의미를 가지는 OS 스케줄러의 구조와 의미에 대해 설명했습니다. 두번째 파트에서는 Go에서 동시성 코드를 작성하는데 중요한 의미를 자지는 Go 스케줄러에 대해 설명했습니다. 이 글에서는 OS와 Go 스케줄러의 구조와 의미를 결합하여 동시성에 대해 더 깊이 설명하겠습니다.
이 글의 목표는 다음과 같습니다.
- 작업부하가 동시성을 제공하기 위해 적합한지 결정할 지침을 제공합니다.
- 다른 종류의 작업부하가 어떻게 동작하는지, 그에 따른 엔지니어링 의사결정은 어떻게 하는지 보여줍니다.
동시성이란 무엇입니까
동시성은 “순서를 지키지 않는” 실행을 의미합니다. 그러기 위해서 일련의 명령어를 처리할 때 순차적으로 실행할 경우와 아닐 경우가 동일한 결과를 만들어내는 것을 보장해야 합니다. 여러분의 문제가 순서를 지키지 않는 실행이 가치 있을 만하다는 것이 분명해야 합니다. 이 때 가치는 복잡한 비용을 지불하더라도 충분한 성능향상이 일어나야 한다는 것입니다. 문제에 따라서는 순서를 지키지 않는 실행이 불가능하거나 말이 안 될 수도 있습니다.
동시성과 병렬성이 다르다는 것을 이해하는 것도 중요합니다. 병렬성은 두 개 이상의 명령어를 동시에 실행하는 것을 의미합니다. 이것은 동시성과는 다른 개념입니다. 병렬성은 2개 이상의 OS/하드웨어 쓰레드가 있고 독립적으로 명령을 수행하는 2개 이상의 고루틴을 가지고 있는 경우에만 가능합니다.
그림1 : 동시성 vs 병렬성
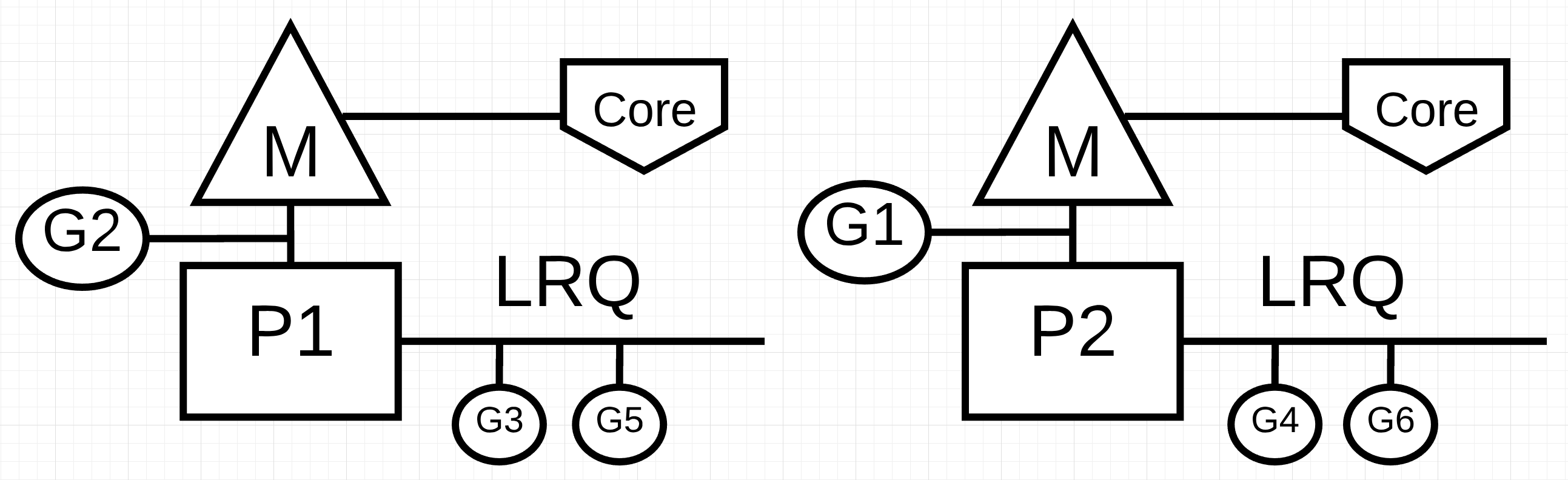
그림 1에서 각각 독립적인 OS 쓰레드(M)이 독립적인 하드웨어 쓰레드(코어)에 연결된 두 개의 논리 프로세서(P)를 볼 수 있습니다. 두 개의 고루틴(G1과 G2)이 병렬 실행되고 있으며, 각각의 OS/하드웨어 쓰레드에서 명령을 병렬 실행하는 것을 볼 수 있습니다. 각 논리 프로세서 내에서 3개의 고루틴이 차례로 각 OS 쓰레드를 공유합니다. 이 고루틴들은 동시성을 가지며, 특정 순서없이 명령을 실행하고 OS 쓰레드 시간을 공유합니다.
이것이 문제입니다. 병렬 처리가 없는 동시성을 활용하면 처리가 실제로 느려질 수 있습니다. 또 흥미로운 것은 동시성을 병렬성과 함께 사용해도 생각보다 큰 성능 향상을 얻지 못할 수도 있습니다.
작업부하
순서를 지키지 않는 실행이 가능하고 의미있는 경우는 어떻게 알 수 있습니까? 작업부하의 유형을 이해하는 것은 좋은 방법입니다. 동시성을 생각할 때 중요한 두 종류의 작업부하가 있습니다.
- CPU 바운드: 고루틴이 자연스럽게 대기상태로 변경되지 않는 작업입니다. 지속적으로 연산을 수행합니다. 파이의 N번째 자릿수를 계산하는 쓰레드는 CPU 바운드가 됩니다.
- IO 바운드: 고루틴이 자연스럽게 대기상태로 변경되는 작업입니다. 이 작업은 네트워크를 통해 리소스에 접근하거나, 운영체제의 시스템 호출을 하거나, 이벤트가 발생할 때까지 대기하고 있습니다. 파일을 읽는 고루틴은 IO 바운드입니다. 고루틴을 대기하게 하는 동기화 이벤트(뮤텍스, 아토믹)도 이 범주에 포함됩니다.
CPU 바운드 작업에 동시성을 활용하려면 병렬 처리가 필요합니다. 고루틴이 자연스럽게 상태를 변경하지 못하기 때문에 여러 고루틴을 처리하는 단일 OS/하드웨어 쓰레드는 효율적이지 않습니다. OS/하드웨어 쓰레드보다 고루틴 수가 많으면 OS 쓰레드로 이동하고 다시 돌아오는 대기시간 때문에 실행속도가 느려질 수 있습니다. 컨텍스트 스위치는 작업부하에 대해 “Stop The World” 이벤트를 발생시킵니다. 스위치 중에는 어떤 작업도 실행될 수 없기 때문입니다.
IO 바운드 작업에 동시성을 사용하기 위해 병렬 처리는 필요하지 않습니다. 고루틴이 자연스럽게 상태를 변경하기 때문에 OS/하드웨서 쓰레드가 여러 고루틴을 효율적으로 처리할 수 있습니다. OS/하드웨어 쓰레드보다 고루틴이 많아도 컨텍스트 스위치가 “Stop The World” 이벤트를 발생시키지 않기 때문에 작업 속도가 빨라질 수 있습니다. 작업부하는 자연스럽게 멈추게 되고 이것은 OS/하드웨어 쓰레드를 대기상태로 두는 대신 다른 고루틴이 효율적으로 사용하게 합니다.
하드웨어당 쓰레드 당 고루틴이 얼마일때 최고의 처리량을 제공하는지 어떻게 알 수 있습니까? 고루틴이 너무 작으면 대기시간이 많습니다. 고루틴이 더무 많으면 컨텍스트 스위치 시간이 길어집니다. 이것은 이 글을 범위를 넘어서며 당신이 생각해야 하는 내용입니다.
지금은 작업부하가 동시성을 사용할 때 병렬처리가 필요한 경우를 확인하기 위해 약간의 코드를 살펴보겠습니다.
숫자 더하기
이런 의미를 이해하고 시각화하기 위해 복잡한 코드는 필요하지 않습니다. 정수 컬렉션을 합하는 add 함수를 살펴보겠습니다.
목록 1 https://play.golang.org/p/r9LdqUsEzEz
36 func add(numbers []int) int {
37 var v int
38 for _, n := range numbers {
39 v += n
40 }
41 return v
42 }
목록 1의 36번째 줄에서 add 함수가 선언되어 정수 컬렉션의 합을 반환합니다. 37번째 줄에서 v 변수를 선언합니다. 38번째 줄에서 컬렉션을 선형적으로 순회하여 39번째 줄에서 현재 합계에 더합니다. 마지막으로 41번째 줄은 최종 합계를 반환합니다.
질문: add 함수가 순서를 지키지 않는 실행에 적합한 작업입니까? 저는 그렇다고 생각합니다. 정수 컬렉션은 작은 목록으로 나뉘어 동시에 처리될 수 있습니다. 모든 작은 목록이 합해지면 합해진 목록을 모아 순차적인 버전과 동일한 결과를 만들 수 있습니다.
하지만, 또 다른 질문이 있습니다. 최고의 처리량을 얻으려면 몇 개의 작은 목록을 만들고 독립적으로 처리해야 합니까? 이 질문에 답하려면 add 함수에서 어떤 종류의 작업부하가 수행 중인지 알아야 합니다. add 함수는 순수한 수학 연산만 하고 자연스러운 대기상태에 들어가지 않기 때문에 CPU 바운드 작업입니다. 이는 처리량을 높이기 위해 OS/하드웨어 스레드 당 하나의 고루틴을 사용해야 하는 것을 의미합니다.
아래 목록 2는 동시성 버전의 add입니다.
참고: 동시성 버전의 add를 작성할 때 여러가지 방법이 있습니다. 저의 구현에 집착하지 마십시오. 만약 더 읽기 쉽고 성능이 좋은 버전을 가지고 있다면 공유바랍니다.
목록 2 https://play.golang.org/p/r9LdqUsEzEz
44 func addConcurrent(goroutines int, numbers []int) int {
45 var v int64
46 totalNumbers := len(numbers)
47 lastGoroutine := goroutines - 1
48 stride := totalNumbers / goroutines
49
50 var wg sync.WaitGroup
51 wg.Add(goroutines)
52
53 for g := 0; g < goroutines; g++ {
54 go func(g int) {
55 start := g * stride
56 end := start + stride
57 if g == lastGoroutine {
58 end = totalNumbers
59 }
60
61 var lv int
62 for _, n := range numbers[start:end] {
63 lv += n
64 }
65
66 atomic.AddInt64(&v, int64(lv))
67 wg.Done()
68 }(g)
69 }
70
71 wg.Wait()
72
73 return int(v)
74 }
목록2에서 add 함수의 동시성 버전인 addConcurrent가 제공됩니다. 순차 버전이 5줄의 코드를 사용하는 것과 달리 동시성 버전은 26줄의 코드를 사용합니다. 많은 코드가 있으므로 중요한 줄만 설명하겠습니다.
줄 48: 각 고루틴은 고유하지만 적은 수의 목록을 가집니다. 목록의 크기는 컬렉션의 크기를 고루틴의 수로 나눈 값입니다.
줄 53: 작업을 하기 위해 고루틴 풀이 생성됩니다.
줄 57-59: 마지막 고루틴은 다른 고루틴에서 작업하지 않은 나머지 숫자 목록을 더하게 됩니다.
줄 66: 작은 목록의 합이 최종 결과로 더해집니다.
동시성 버전은 순차 버전보다 확실히 복잡합니다. 하지만 가치 있는 일입니까? 이 질문에 답하는 가장 좋은 방법은 벤치마크를 작성하는 것입니다. 저는 가비지 컬렉터가 꺼진 상태에서 1,000만 개의 콜렉션을 사용했습니다. add 함수를 사용하는 순차 버전과 addConcurrent 함수를 사용하는 동시성 버전이 있습니다.
목록 3
func BenchmarkSequential(b *testing.B) {
for i := 0; i < b.N; i++ {
add(numbers)
}
}
func BenchmarkConcurrent(b *testing.B) {
for i := 0; i < b.N; i++ {
addConcurrent(runtime.NumCPU(), numbers)
}
}
목록 3은 벤치마크 함수를 보여줍니다. 다음은 모든 고루틴이 단일 OS/하드웨어 쓰레드만 사용할 수 있는 경우 결과입니다. 순차버전은 1개의 고루틴을 사용하고, 동시성 버전은 8개의 고루틴을 사용하고 있습니다. 이 경우 동시성 버전은 병렬처리 없이 동시성을 사용합니다.
목록 4
10 Million Numbers using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITHOUT Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound
BenchmarkSequential 1000 5720764 ns/op : ~10% Faster
BenchmarkConcurrent 1000 6387344 ns/op
BenchmarkSequentialAgain 1000 5614666 ns/op : ~13% Faster
BenchmarkConcurrentAgain 1000 6482612 ns/op
참고: 로컬 컴퓨터에서 벤치마크를 하는 것에는 많은 고려사항이 있습니다. 이 상황에는 벤치마크가 부정확할 수 있는 요인이 많습니다. 최대한 장비가 대기상태임을 확인하고 벤치마크를 여러 번 실행하십시오. 결과에 일관성이 있는지 확인이 필요합니다. 테스트 도구로 벤치마크를 두 번 실행하면 일관된 결과를 얻을 수 있습니다.
목록 4의 벤치마크는 고루틴이 하나의 OS/하드웨어 쓰레드만 사용할 수 있는 경우 순차 버전이 동시성 버전보다 10~13% 빠른 걸 보여줍니다. 이것은 동시성 버전이 단일 OS 쓰레드의 컨텍스트 스위치와 고루틴 관리에서 오버헤드를 가지기 때문에 예상할 수 있었던 결과입니다.
다음은 OS/하드웨어 쓰레드가 각 고루틴에서 사용가능한 경우의 결과입니다. 제 장비에서 순차 버전은 1개의 고루틴을 사용하며 동시성 버전은 8개의 고루틴을 사용하고 있습니다. 이 경우 동시성 버전은 병렬성을 사용합니다.
목록 5
10 Million Numbers using 8 goroutines with 8 cores
2.9 GHz Intel 4 Core i7
Concurrency WITH Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 8 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound
BenchmarkSequential-8 1000 5910799 ns/op
BenchmarkConcurrent-8 2000 3362643 ns/op : ~43% Faster
BenchmarkSequentialAgain-8 1000 5933444 ns/op
BenchmarkConcurrentAgain-8 2000 3477253 ns/op : ~41% Faster
목록 5의 벤치마크에서 고루틴에 대해 개별 OS/하드웨어 쓰레드를 사용할 경우 동시성 버전이 순차 버전보다 41~43% 빠릅니다. 이것은 모든 고루틴이 병렬로 실행되기 때문입니다. 동시에 8개의 고루틴이 작업을 수행합니다.
정렬
모든 CPU 바인딩 작업이 동시성에 적합하지 않다는 것을 이해하는 것이 중요합니다. 주로 작업을 중단하거나 결과를 합하는 데 많은 비용이 들 때 이는 사실입니다. 대표적인 사례는 버블소트입니다. Go에서 버블소트를 구현한 다음 코드를 보십시오.
목록 6 https://play.golang.org/p/S0Us1wYBqG6
01 package main
02
03 import "fmt"
04
05 func bubbleSort(numbers []int) {
06 n := len(numbers)
07 for i := 0; i < n; i++ {
08 if !sweep(numbers, i) {
09 return
10 }
11 }
12 }
13
14 func sweep(numbers []int, currentPass int) bool {
15 var idx int
16 idxNext := idx + 1
17 n := len(numbers)
18 var swap bool
19
20 for idxNext < (n - currentPass) {
21 a := numbers[idx]
22 b := numbers[idxNext]
23 if a > b {
24 numbers[idx] = b
25 numbers[idxNext] = a
26 swap = true
27 }
28 idx++
29 idxNext = idx + 1
30 }
31 return swap
32 }
33
34 func main() {
35 org := []int{1, 3, 2, 4, 8, 6, 7, 2, 3, 0}
36 fmt.Println(org)
37
38 bubbleSort(org)
39 fmt.Println(org)
40 }
목록 6에는 Go로 작성된 버블소트가 있습니다. 이 정렬 알고리즘은 모든 컬렉션을 순회하며 모든 경로에서 값을 교환합니다. 목록의 정렬 정도에 따라 모든 항목을 정렬하기 위해 컬렉션을 여러 번 순회할 수 있습니다.
질문: bubbleSort 함수는 순서가 보장되지 않는 실행에 적합한 작업입니까? 저는 아니라고 생각합니다. 정수 컬렉션은 작은 목록으로 나뉘어 동시에 정렬할 수 있습니다. 하지만 모든 작업이 완료된 후 작은 목록을 함께 정렬하는 효율적인 방법은 없습니다. 다음은 동시성 버전의 버블소트입니다.
목록 8
01 func bubbleSortConcurrent(goroutines int, numbers []int) {
02 totalNumbers := len(numbers)
03 lastGoroutine := goroutines - 1
04 stride := totalNumbers / goroutines
05
06 var wg sync.WaitGroup
07 wg.Add(goroutines)
08
09 for g := 0; g < goroutines; g++ {
10 go func(g int) {
11 start := g * stride
12 end := start + stride
13 if g == lastGoroutine {
14 end = totalNumbers
15 }
16
17 bubbleSort(numbers[start:end])
18 wg.Done()
19 }(g)
20 }
21
22 wg.Wait()
23
24 // Ugh, we have to sort the entire list again.
25 bubbleSort(numbers)
26 }
목록 8에서 bubbleSortConcurrent 함수는 bubbleSort 함수의 동시성 버전입니다. 이것은 여러 고루틴을 사용하여 목록의 일부를 동시에 정렬합니다. 하지만 남은 것은 분할되어 정렬된 값 목록입니다. 전체 목록이 정렬되어 있지 않으면 24번 째 줄에서 다시 한 번 정렬해야 합니다.
목록 9
Before:
25 51 15 57 87 10 10 85 90 32 98 53
91 82 84 97 67 37 71 94 26 2 81 79
66 70 93 86 19 81 52 75 85 10 87 49
After:
10 10 15 25 32 51 53 57 85 87 90 98
2 26 37 67 71 79 81 82 84 91 94 97
10 19 49 52 66 70 75 81 85 86 87 93
버블소트는 목록을 순회하면 교체하므로 25번 째 줄의 bubbleSort 호출은 동시성 사용으로 인한 잠재적 이득을 무효화합니다. 버블소트에서는 동시성을 사용하여 성능을 향상시킬 수 없습니다.
파일 읽기
두 개의 CPU 바운드 작업부하를 살펴보았는데, IO 바운드 작업부하는 어떨 것 같습니까? 고루틴이 자연스럽데 대기상태로 변화될 때는 의미가 다른가요? 파일을 읽고 텍스트를 검색하는 IO 바운드 작업부하를 살펴보겠습니다.
첫 번째 버전은 find라는 함수의 순차적인 버전입니다.
목록 10 https://play.golang.org/p/8gFe5F8zweN
42 func find(topic string, docs []string) int {
43 var found int
44 for _, doc := range docs {
45 items, err := read(doc)
46 if err != nil {
47 continue
48 }
49 for _, item := range items {
50 if strings.Contains(item.Description, topic) {
51 found++
52 }
53 }
54 }
55 return found
56 }
목록 10에 순차적인 버전의 find 함수가 있습니다. 43번 째 줄에 found라는 변수가 선언되어 문서 안에 topic이 발견된 횟수를 기록합니다. 다음 44번 째 줄에서 문서를 반복하고 45번 째 줄에서 일기 기능을 사용하여 읽습니다. 마지막으로 49-53 줄에서 strings 패키지의 Contains 함수는 문서에서 읽은 아이템들의 컬렉션 안에 topic이 있는지 확인합니다. topic이 발견되면 found가 1씩 증가합니다.
다음은 find가 호출하는 read 함수의 구현입니다.
목록 11 https://play.golang.org/p/8gFe5F8zweN
33 func read(doc string) ([]item, error) {
34 time.Sleep(time.Millisecond) // Simulate blocking disk read.
35 var d document
36 if err := xml.Unmarshal([]byte(file), &d); err != nil {
37 return nil, err
38 }
39 return d.Channel.Items, nil
40 }
목록 11의 read 함수는 1 밀리초 동안의 time.Sleep 호출로 시작합니다. 이것은 실제 시스템 호출을 수행하여 디스크에서 문서를 읽는 경우 발생하는 대기시간을 연출하는데 사용됩니다. 이 대기시간의 일관성은 동시성 버전과 순차적 버전에 대한 find 성능을 측정하는 데 중요합니다. 다음으로 35-59 행에서 전역변수 file에 저장된 모의 XML 문서를 언마샬합니다. 마지막으로 39행에서 아이템 컬렉션이 반환됩니다.
다음으로 동시성 버전입니다.
참고: 동시성 버전의 find를 작성하는 여러 방법이 있습니다. 저의 특정한 구현에 집착하지 마십시오. 만약 더 읽기 쉽고 성능이 좋은 버전을 가지고 있다면 공유바랍니다.
목록 12 https://play.golang.org/p/8gFe5F8zweN
58 func findConcurrent(goroutines int, topic string, docs []string) int {
59 var found int64
60
61 ch := make(chan string, len(docs))
62 for _, doc := range docs {
63 ch <- doc
64 }
65 close(ch)
66
67 var wg sync.WaitGroup
68 wg.Add(goroutines)
69
70 for g := 0; g < goroutines; g++ {
71 go func() {
72 var lFound int64
73 for doc := range ch {
74 items, err := read(doc)
75 if err != nil {
76 continue
77 }
78 for _, item := range items {
79 if strings.Contains(item.Description, topic) {
80 lFound++
81 }
82 }
83 }
84 atomic.AddInt64(&found, lFound)
85 wg.Done()
86 }()
87 }
88
89 wg.Wait()
90
91 return int(found)
92 }
목록 12에서 find 함수의 동시성 버전인 findConcurrent가 제공됩니다. 순차 버전은 13행이지만 동시성 버전은 30행입니다. 동시성 버전의 구현목표는 예상할 수 없는 문서 수를 처리하는데 사용되는 고루틴의 수를 제어하는 것이었습니다. 고루틴 풀에 피드하는 채널을 사용하는 풀링 패턴이 제 선택이었습니다.
많은 코드가 있으므로 중요한 줄만 강조하겠습니다.
줄 61-64: 채널이 생성되고 처리해야 할 문서가 채워집니다.
줄 65: 문서가 모두 처리되면 고루틴 풀이 자연스럽게 종료되도록 채널이 닫힙니다.
줄 70: 고루틴 풀이 생성됩니다.
줄 73-83: 풀의 각 고루틴은 채널에서 문서를 수신하고 메모리로 읽어들여 내용을 확인합니다. 만약 일치하는 내용이 있으면 lFound는 증가합니다.
줄 84: 개별 고루틴의 결과가 최종적으로 합해집니다.
동시성 버전은 순차 버전보다 확실히 복잡합니다. 그럼 이것의 가치는 어떠합니까? 이 질문에 대답하는 가장 좋은 방법은 벤치마크를 만드는 것입니다. 벤치마크를 위해 가비지 컬렉터가 꺼진 채로 1000개의 문서를 사용했습니다. 순차 버전인 find와 동시성 버전인 findConcurrent가 있습니다.
목록 13
func BenchmarkSequential(b *testing.B) {
for i := 0; i < b.N; i++ {
find("test", docs)
}
}
func BenchmarkConcurrent(b *testing.B) {
for i := 0; i < b.N; i++ {
findConcurrent(runtime.NumCPU(), "test", docs)
}
}
목록 13은 벤치마크 함수를 보여줍니다. 아래는 단일 OS/하드웨어 쓰레드를 사용할 경우의 결과입니다. 순차 버전은 하나의 고루틴을 사용하고 공시성 버전은 내 컴퓨터에서 8개의 고루틴을 사용하고 있습니다. 이 경우 동시성 버전은 병렬 처리없이 동시성을 활용합니다.
목록 14
10 Thousand Documents using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITHOUT Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound
BenchmarkSequential 3 1483458120 ns/op
BenchmarkConcurrent 20 188941855 ns/op : ~87% Faster
BenchmarkSequentialAgain 2 1502682536 ns/op
BenchmarkConcurrentAgain 20 184037843 ns/op : ~88% Faster
목록 14의 벤치마크 결과에 따르면 고루틴이 단일 OS/하드웨어 쓰레드만 사용할 수 있는 경우 동시성 버전은 순차 버전보다 약 77-88% 빠릅니다. 이것은 고루틴이 단일 OS/하드웨어 쓰레드를 효율적으로 공유하기 떄문에 기대했던 결과와 같습니다. read 호출에서 각 고루틴에 발생시키는 자연스러운 컨텍스트 스위칭은 단일 OS/하드웨어 쓰레드에서 더 많은 작업을 수행할 수 있게 합니다.
다음은 병렬성을 이용해 동시성을 사용할 때의 벤치마크입니다.
목록 15
10 Thousand Documents using 8 goroutines with 1 core
2.9 GHz Intel 4 Core i7
Concurrency WITH Parallelism
-----------------------------------------------------------------------------
$ GOGC=off go test -run none -bench . -benchtime 3s
goos: darwin
goarch: amd64
pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound
BenchmarkSequential-8 3 1490947198 ns/op
BenchmarkConcurrent-8 20 187382200 ns/op : ~88% Faster
BenchmarkSequentialAgain-8 3 1416126029 ns/op
BenchmarkConcurrentAgain-8 20 185965460 ns/op : ~87% Faster
목록 15의 벤치마크에서 추가 OS/하드웨어 쓰레드가 성능을 향상시키지 않는다는 것을 알 수 있습니다.
결론
이 글의 목표는 작업부하가 동시성 사용에 적합한 지 여부를 결정하기 위해 고려해야 할 것에 대한 지침의 제공이었습니다. 저는 다른 유형의 알고리즘과 작업부하에 대한 예제를 제공하여 의미적인 차이와 엔지니어링 결정에서 고려되어야 할 부분에 대해 안내했습니다.
IO 바운드 작업부하에서 병렬 처리가 성능에 큰 영향을 주지 않는다는 것을 분명하게 알 수 있습니다. CPU 바운드 작업에서는 그 반대입니다. 버블 정렬과 같은 알고리즘의 경우에 동시성을 사용하면 성능의 이득없이 복잡도만 추가됩니다. 작업부하가 동시성에 적합한지 확인하고 어떤 의미를 가지는지 아는 것이 중요합니다.