(번역) Go 스케줄링 파트 2
원문: https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
프렐류드
Go 스케줄러의 구조와 의미 이해를 제공하는 3부작의 세 번째 글입니다. 이 글은 Go 스케줄러에 중점을 둡니다.
세 시리즈의 인덱스:
서론
이 시리즈의 첫번째 파트에서는 Go 스케줄러의 의미를 이해하는데 중요한, 운영체제 스케줄러에 대해 설명했습니다. 이 글에서는 상위수준의 동작에 초점읠 맞춰 Go 스케줄러가 어떻게 동작는지 설명할 것이비나. Go 스케줄러는 복잡한 시스템이며 기술적인 세부사항은 중요하지 않습니다. 중요한 것은 어떻게 동작하고 행동하는지에 대한 개념을 갖는 것입니다. 그렇다면 더 나은 엔지니어링 결정을 내릴 수 있습니다.
프로그램 시작
Go 프로그램이 시작되면 호스트 시스템에서 식별되는 모든 가상 코어에 대해 논리 프로세서(P)가 제공됩니다. 물리적 코어마다 여러개의 하드웨어 쓰레드가 있는 하드웨어(하이퍼쓰레드)를 사용하는 경우 각 하드웨어 쓰레드는 Go 프로그램에 가상 코어로 제공됩니다. 이를 더 잘 이해하기 위해 제 MacBook Pro의 시스템을 보겠습니다.
그림 1

4개의 물리적 코어를 보유한 단일 프로세서가 있습니다. 이 보고서에 없는 내용은 물리적 코어당 하드웨어 쓰레드 수입니다. Intel Core i7 프로세서는 하이퍼쓰레드를 지원합니다. 즉, 실제 코어당 2개의 하드웨어 쓰레드가 있습니다. 그러므로 Go 프로그램은 8개의 가상 코어를 이용해 OS 쓰레드를 병렬로 실행할 수 있습니다.
이것을 테스트하기 위해 다음 프로그램을 준비했습니다:
Listing 1
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU returns the number of logical
// CPUs usable by the current process.
fmt.Println(runtime.NumCPU())
}
제 로컬 컴퓨터에서 이 프로그램을 실행하면 NumCPU() 함수 호출의 결과는 8입니다. 제 컴퓨터에서 실행하는 모든 Go 프로그램에 8P가 제공됩니다.
모든 P에는 OS 쓰레드(M)가 할당됩니다. M은 기계를 의미합니다. 이 쓰레드는 여전히 운영체제에 의해 관리되며 운영체제는 이전 글에서 설명한 것처럼 코어에 쓰레드를 배치해야 합니다. 즉, 제 컴퓨터에서 Go 프로그램을 실행하면 작업을 실행하는 데 사용할 수 있는 8개의 쓰레드가 있으며 각 쓰레드는 개별적으로 P에 등록됩니다.
모든 Go 프로그램에는 실행경로인 고루틴(G)이 초기에 제공됩니다. 고루틴은 기본적으로 코루틴이지만 Go이기 떄문 C를 G로 바꾸고 고루틴이란 단어를 사용합니다. 고루틴을 애플리케이션 수준의 쓰레드로 생각할 수 있으며 여러 면에서 OS 쓰레드와 유사합니다. OS 쓰레드가 코어에서 컨텍스트 스위칭 하듯이, 고루틴은 M에서 컨텍스트 스위칭 합니다.
퍼즐의 마지막 부분은 실행 큐입니다. Go 스케줄러에는 글로벌 실행 큐(GRQ)와 로컬 실행 큐(LRQ) 두가지 실행 큐가 있습니다. 각 P에는 P의 컨텍스트 내에서 실행되도록 할당된 고루틴들을 관리하는 LRQ가 있습니다. 이 고루틴들은 해당 P에 할당된 M의 컨텍스트 전환을 번갈아 수행합니다. GRQ는 아직 할당되지 않은 고루틴용입니다. 고루틴을 GRQ에서 LRQ로 옮기는 작업에 대해서는 이후에 이야기하겠습니다.
그림 2는 이러한 구성요소를 모두 보여줍니다.
그림 2
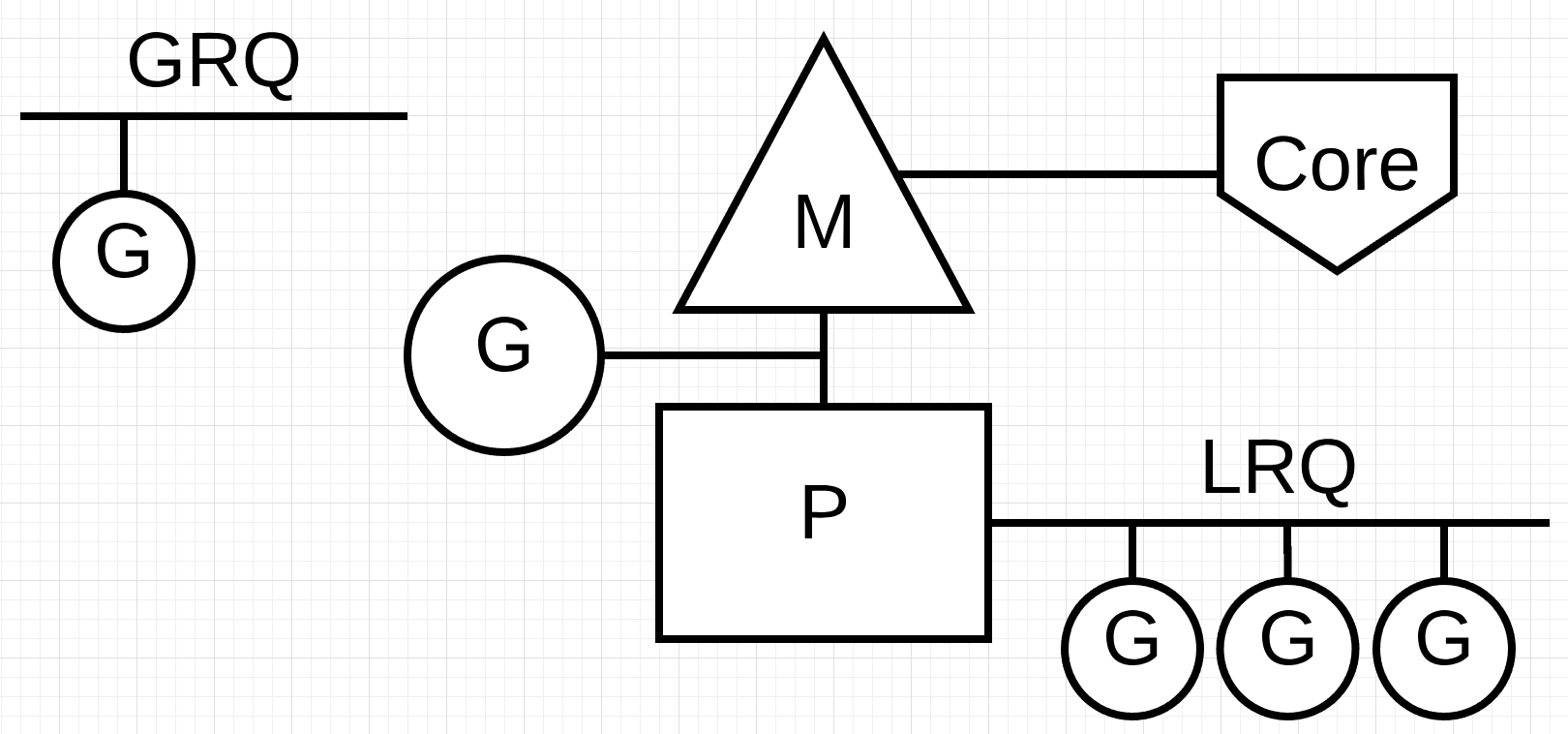
스케줄러 협력
첫번째 글에서 설명한 것처럼, OS 스케줄러는 강탈형 스케줄러입니다. 이는 본질적으로 스케줄러가 주어신 시간에 무엇을 할 것인지 예측할 수 없다는 것을 의미합니다. 커널이 결정을 하며 모든 것이 비결정적입니다. OS 위에서 실행되는 애플리케이션은 atomic이나 mutex 같은 동기화 기능을 사용하지 않는 한 스케줄링을 통해 커널 내부에서 발생하는 일에 관여하지 않습니다.
Go 스케줄러는 Go 런타임의 일부이며 Go 런타임은 애플리케이션에 내장되어 있습니다. 이것은 Go 스케줄러가 커널 위의 사용자 공간에서 실행됨을 의미합니다. 현재 Go 스케줄러 구현은 강탈형이 아니라 협력형입니다. 협력형 스케줄러란 스케줄링을 결정하기 위해 코드의 안전 지점에서 발생하는 잘 정의된 사용자 공간 이벤트를 필요로 한다는 것을 의미합니다.
Go 스케줄러가 훌륭한 점은 강탈형으로 느껴진다는 것입니다. 여러분은 Go 스케줄러가 수행할 작업을 예측할 수 없습니다. 이는 협력 스케줄러에 대한 의사결정이 개발자의 손에 있지 않고 Go 런타임에 있기 때문입니다. Go 스케줄러를 강탈형이며 비결정적이라고 생각하는 것은 중요합니다.
고루틴 상태
쓰레드와 마찬가지로, 고루틴도 세가지 고수준 상태를 가집니다. 이것은 Go 스케줄러가 고루틴을 동작시키는 방식을 결정합니다. 고루틴은 세가지 상태 중하나를 가집니다: 대기, 실행가능, 실행.
대기: 고루틴이 멈추고 기다리는 것을 의미합니다. 이는 운영체제(시스템 호출) 또는 동기화 호출(atomic 또는 mutex 명령)을 기다른 것과 같은 이유로 발생할 수 있습니다. 이러한 지연은 성능저하의 근본 원인입니다.
실행가능: 고루틴이 M에서 명령을 실행할 수 있음을 의미합니다. 시간이 필요한 고루틴이 많이 있는 경우 더 오래 기다려야 합니다. 또한 고루틴들이 경쟁함에 따라 각 고루틴이 얻는 시간은 줄어듭니다. 이러한 유형의 지연은 성능저하의 원인이 될 수도 있습니다.
실행: 고루틴인 M에 있고 명령을 실행 중임을 의미합니다. 애플리케이션과 관련된 작업이 실행되며, 모두가 원하는 상태입니다.
컨텍스트 스위칭
Go 스케줄러는 코드의 안전한 지점에서 발생하는 잘 정의된 사용자 공간 이벤트가 필요합니다. 이러한 이벤트와 안전 지점은 함수 호출 내에서 나타납니다. 함수 호출은 Go 스케줄러의 상태에 중요합니다. 현재(Go 1.11 이하) 함수 호출을 하지 않는 루프를 실행하면 스케줄러와 가비지 컬렉터 수준에서 지연이 발생할 수 있습니다. 합리적인 시간 내에 함수 호출을 하는 것이 매우 중요합니다.
참고: Go 스케줄러 내에 비협력 강탈 기법을 적용하여 루프를 강탈형으로 할 수 있도록 하는 1.12에 대한 제안이 있습니다.
스케줄링 결정을 내릴 수 있도록 Go 프로그램에서 발생시키는 네 가지의 이벤트가 있습니다. 그러나 항상 이 중 하나로 인해 결정이 되는 것은 아니며, 스케줄러가 기회를 얻는다는 것을 의미합니다.
키워드 go의 사용 가비지 컬렉션 시스템 호출 동기화 및 오케스트레이션
The use of the keyword go
키워드 go는 고루틴을 만드는 방법입니다. 새로운 고루틴이 생성되면 스케줄러에게 스케줄링 결정을 내릴 기회를 줍니다.
가비지 컬렉션
GC는 자체 고루틴 셋을 사용하기 때문에, 고루틴은 M에서 실행할 시간이 필요합니다. 이것 때문에 GC는 스케줄링에 많은 혼란을 줍니다. 그러나, 스케줄러는 고루틴이 하는 일에 대해 잘 알고 올바른 결정을 합니다. 그 중 하나는 GC 기간 중에는 힙에 접근하는 고루틴을 힙에 접근하지 않는 고루틴으로 컨텍스트 스위칭 하는 것입니다. GC가 일어나는 동안, 많은 스케줄링 결정이 내려집니다.
시스템 호출
고루틴이 M을 차단하게 하는 시스템 호출을 만들면, 스케줄러는 고루틴을 컨텍스트 스위칭할 수 있습니다. 그러나 떄로는 P에 큐잉되어있는 고루틴을 실행하기 위해 새로운 M이 필요합니다. 이것이 어떻게 작동하는지는 다음 섹션에서 자세히 보겠습니다.
동기화 및 오케스트레이션
만약 atomic, mutex, channel 명령어 호출로 고루틴이 블록되면, 스케줄로는 다른 코루틴을 컨텍스트 스위칭하여 실행할 수 있습니다. 고루틴을 다시 실행할 수 있게 되면 다시 큐에 넣고 결국 M에서 컨텍스트 스위칭되어 돌아올 수 있습니다.
비동기 시스템 호출
실행중인 OS에서 시스템 호출을 비동기적으로 처리할 수 있으면, 네트워크 폴러를 이용해 시스템 호출을 효율적으로 처리할 수 있습니다. 이것은 kqueue(맥), epoll(리눅스), iocp(윈도우즈)를 사용하여 수행됩니다.
네트워킹 기반 시스템 호출은 오늘날 많은 OS에 의해 비동기적으로 처리될 수 있습니다. 네트워크 폴러는 기본적으로 네트워킹 작업을 처리하기 때문에 이 이름을 얻었습니다. 스케줄러는 시스템 호출이 발생할 때 고루틴이 M을 차단하는 것을 방지할 수 있습니다. 이것은 새 M을 만들지 않고 M이 P의 LRQ에서 다른 고루틴을 실행하게 할 수 있게 합니다. 이는 OS의 스케줄링 부하를 줄이는 데 도움이 됩니다.
예제로 알아보겠습니다.
그림 3
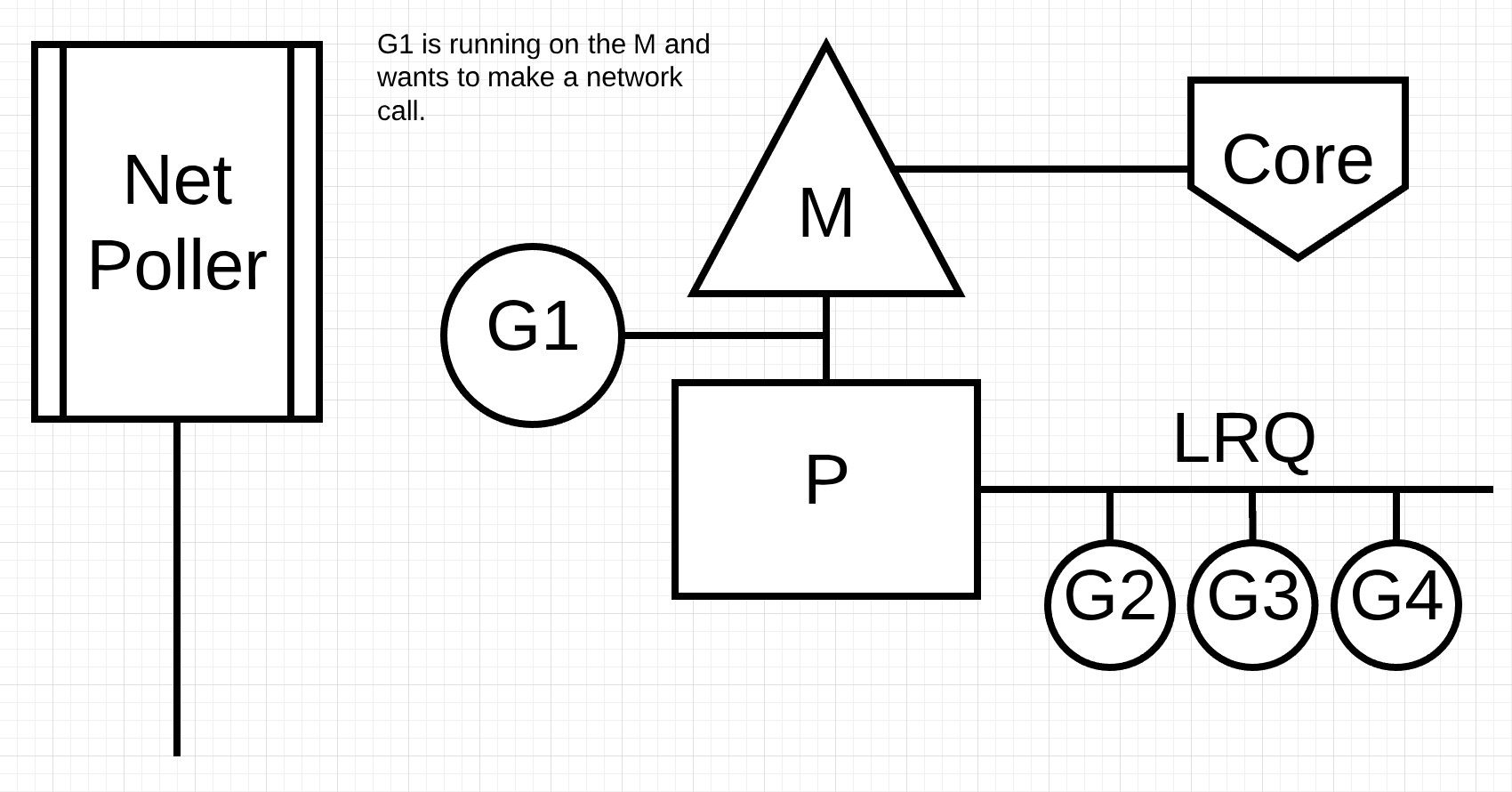
그림 3은 기본 스케줄링 다이어그램을 보여줍니다. 고루틴 1은 M에서 실행중이며 LRQ에 M에서 시간을 받기 위해 기다리는 고루틴이 3개 더 있습니다. 네트워크 폴러는 대기중입니다.
그림 4
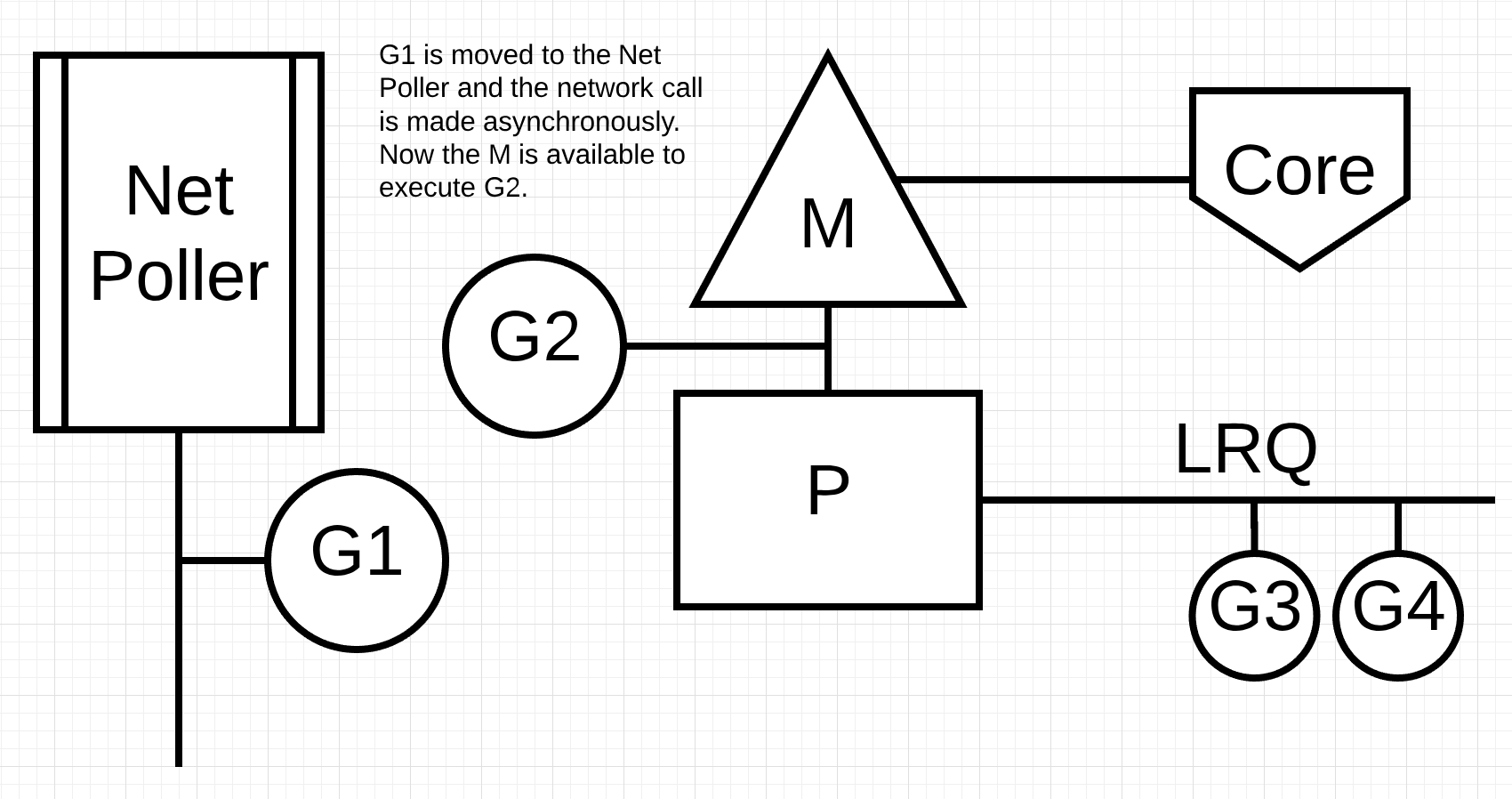
그림 4에서, 고루틴 1은 네트워크 시스템 호출을 원하므로, 네트워크 폴러로 이동하고 비동기 네트워크 시스템 호출이 처리됩니다. 고루틴 1이 네트워크 폴러로 이동하면 M은 이제 LRQ와 다른 고루틴을 실행할 수 있습니다. 이 경우 고루틴 2가 M으로 컨텍스트 스위칭됩니다.
그림 5
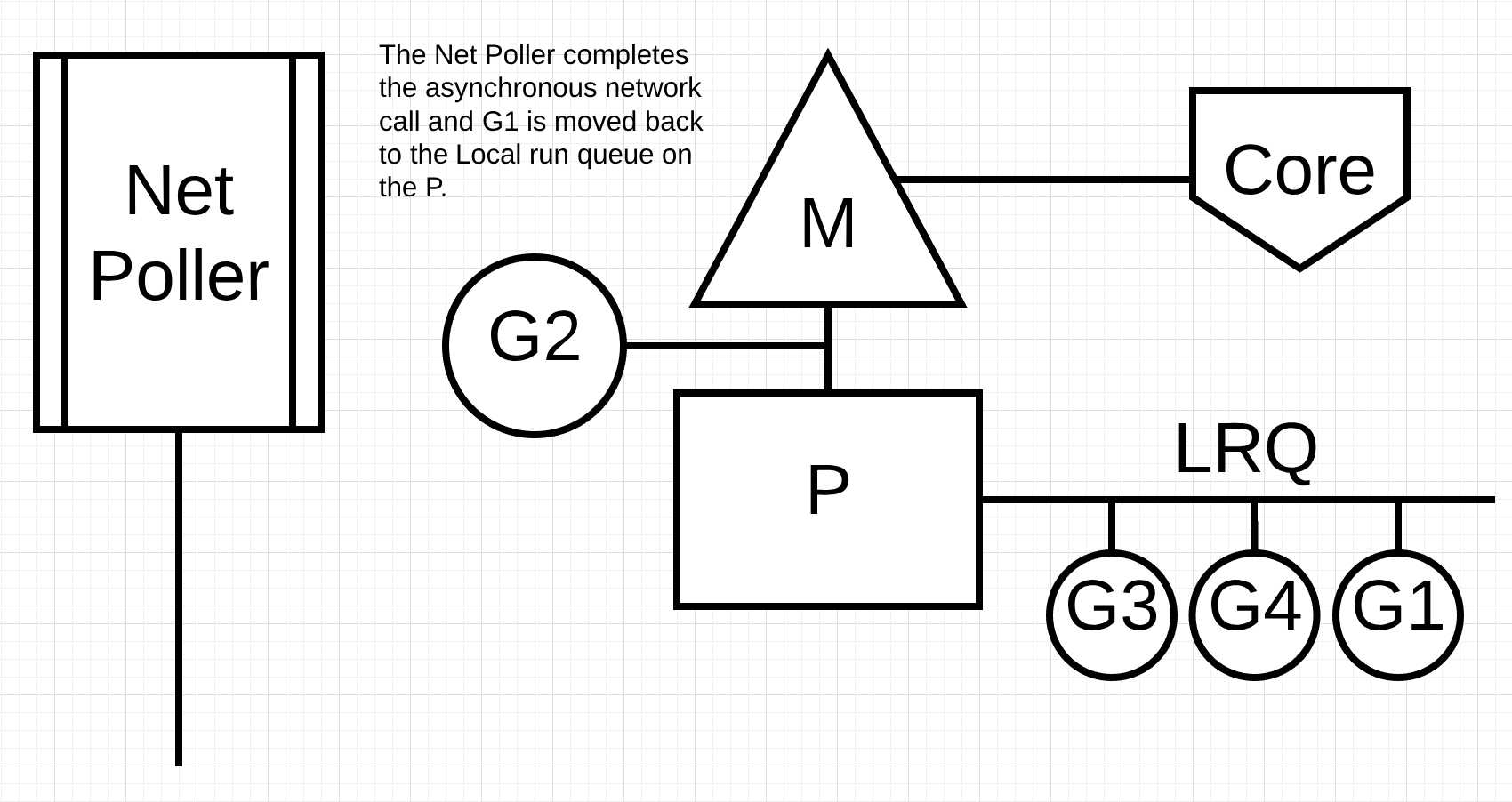
그림 5에서, 비동기 네트워크 시스템 호출은 네트워크 폴러에 의해 완료되고 고루틴 1은 P의 LRQ로 이동한다. 일단 코루틴이 M으로 컨텍스트 스위칭 되면, 다시 실행될 수 있습니다. 여기서 큰 장점은, 네트워크 시스템 호출을 위해 추가 M이 필요하지 않다는 것입니다. 네트워크 폴러에는 OS 쓰레드가 있으며 효율적으로 이벤트 루프를 처리합니다.
동기 시스템 호출
고루틴이 비동기적으로 수행할 수 없는 시스템 호출을 할 떄 어떤 일이 발생할까요? 이 경우 네트워크 폴러를 사용할 수 없으며 고루틴이 M을 차단할 것입니다. 불행하게도 이를 막을 수 있는 방법은 없습니다. 비동기적으로 만들 수 없는 시스템 호출의 한 예는 파일 기반 시스템 호출입니다. CGO를 사용한다면, C 함수를 호출할 때도 M이 차단될 수 있습니다.
참고: 윈도우즈에는 파일 기반 시스템 호출을 비동기적으로 수행할 수 있는 기능이 있습니다. 기술적으로 네트워크 폴러가 사용가능합니다.
M을 차단하게 하는 동기 시스텐 호출(파일 I/O와 같은)에서 어떤 일이 일어나는지 살펴보겠습니다.
그림 6
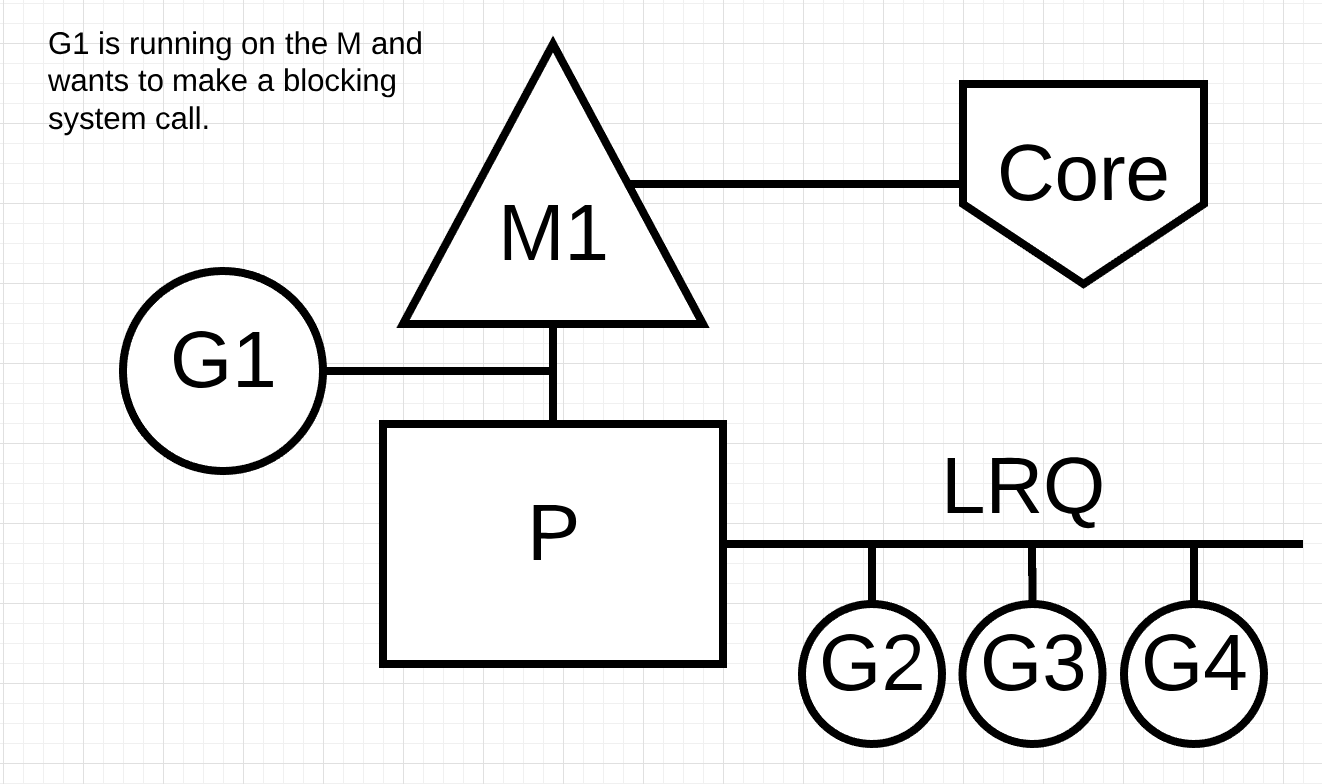
그림 6은 기본 스케줄링 다이어그램을 다시 보여주고 있지만, 고루틴 1은 M1을 차단하는 동기식 시스템 호출을 하고 있습니다.
그림 7
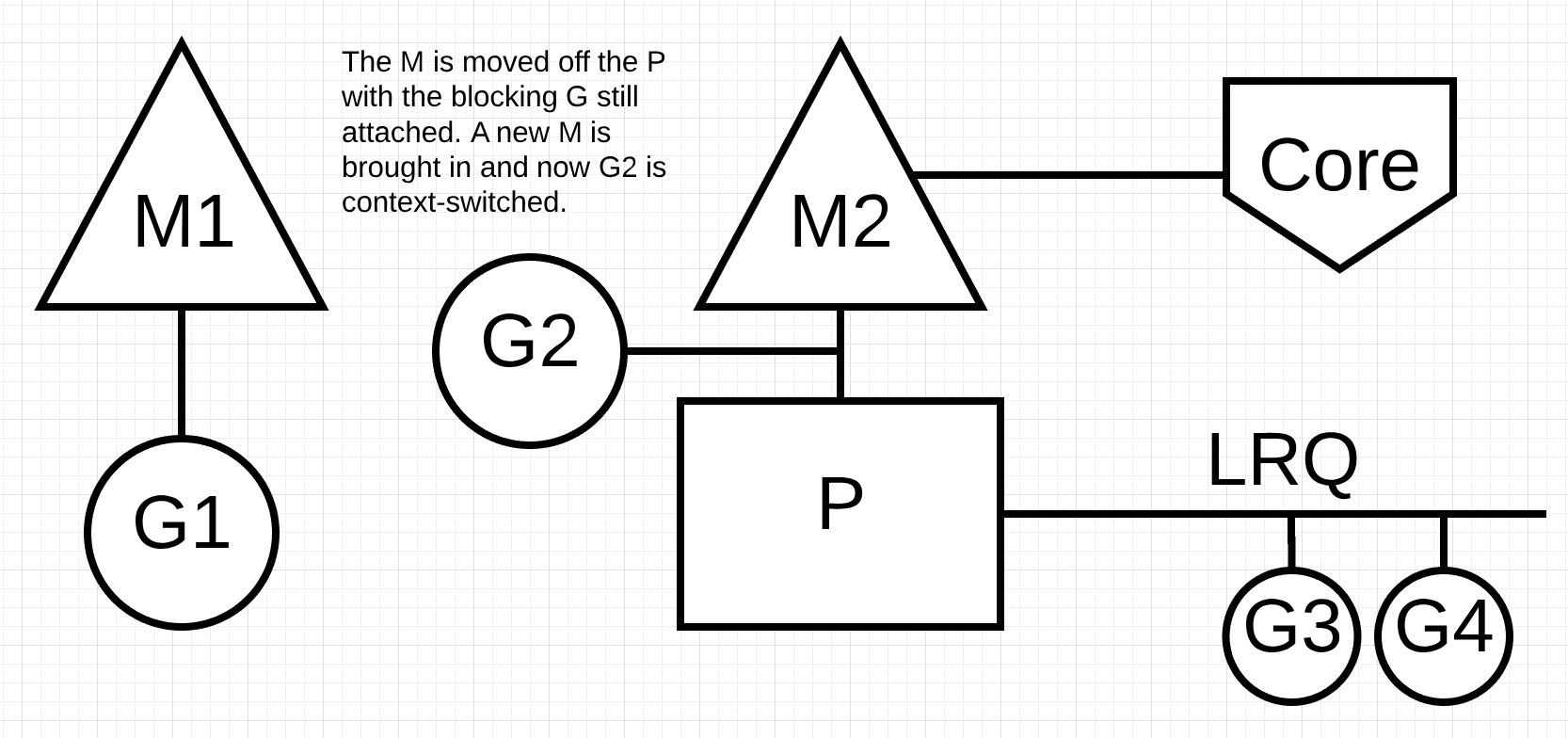
그림 7에서 스케줄러는 고루틴 1이 M을 차단하도록 만든 것을 식별할 수 있습니다. 스케줄러는 차단된 고루틴 1이 연결된 상태로 P에서 M1을 분리합니다. 그 다음 스케줄러는 P를 서비스하기 위해 새로운 M2를 도입합니다. 이 시점에서 고루틴 2는LRQ에서 선택되어 M2로 컨텍스트 스위칭 됩니다. 이전 스왑에 의해 M이 이미 존재하다면, 이 전환은 새로운 M을 생성하는 것보다 빠릅니다.
그림 8
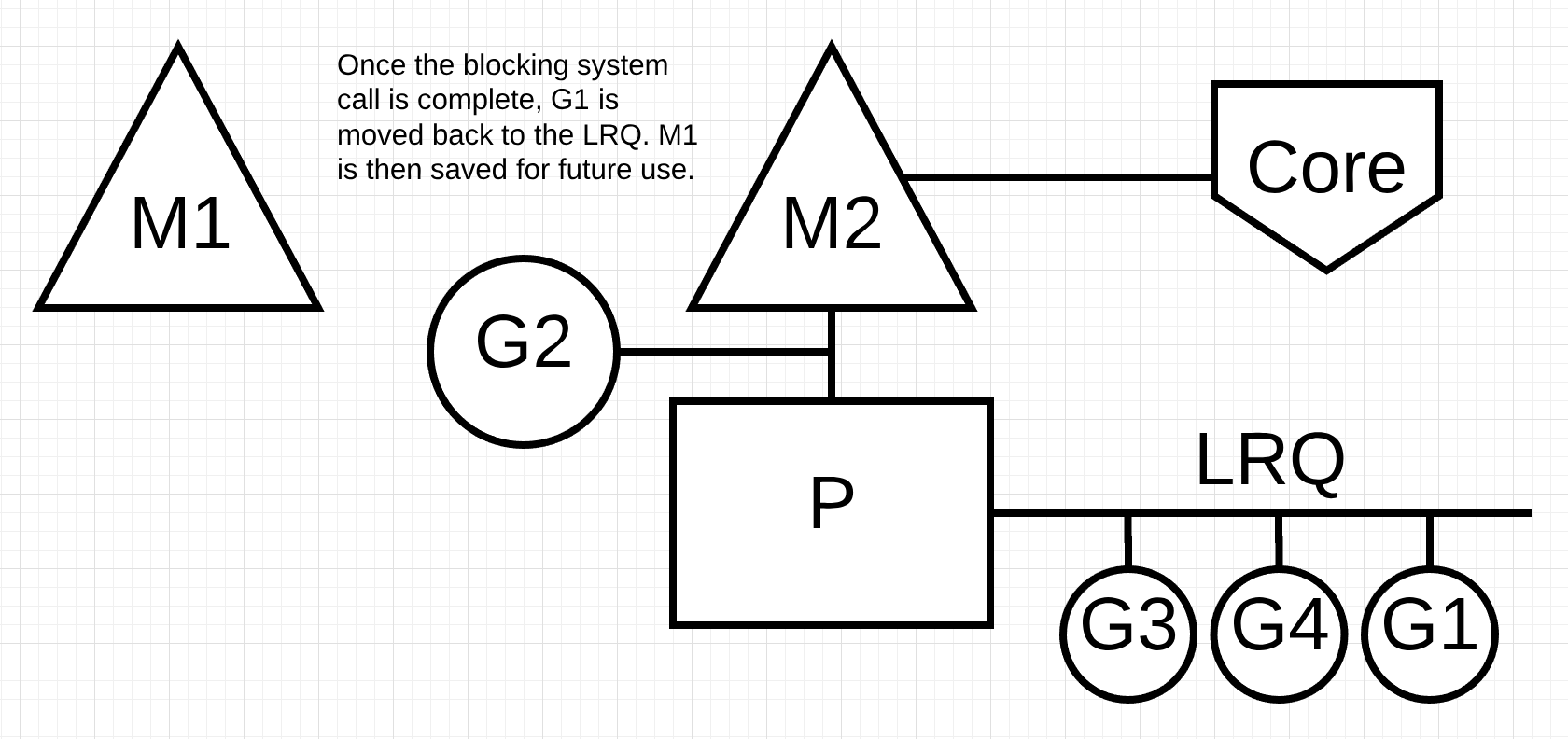
그림 8에서 고루틴 1에 의한 동기 시스템 호출이 끝납니다. 이 시점에서 고루틴 1은 LRQ로 다시 이동하여 P에 의해 다시 서비스 될 수 있습니다. M1은 이런 경우가 또 생길 것에 대비해 대기됩니다.
작업 훔치기
스케줄러의 또다른 측면은 이것이 작업 훔치기 스케줄러라는 것입니다. 이것은 일정 영역에서 효율성에 도움이 됩니다. 한 예로, 위 예의 마지막에서 OS가 컨텍스트 스위칭 해가기 위해 M이 대기 상태가 되었습니다. 이것은 고루틴이 작동가능하더라도 코에에서 M이 컨텍스트 스위칭 되어 돌아오기 전에는 P가 아무 일도 하지 못한다는 것을 의미합니다. 작업 훔치기는 또한 모든 P에 걸쳐 고루틴의 균형을 잡는데 도움이 되므로 작업이 보다 효율적으로 분산되어 수행됩니다.
예제를 봅시다.
그림 9
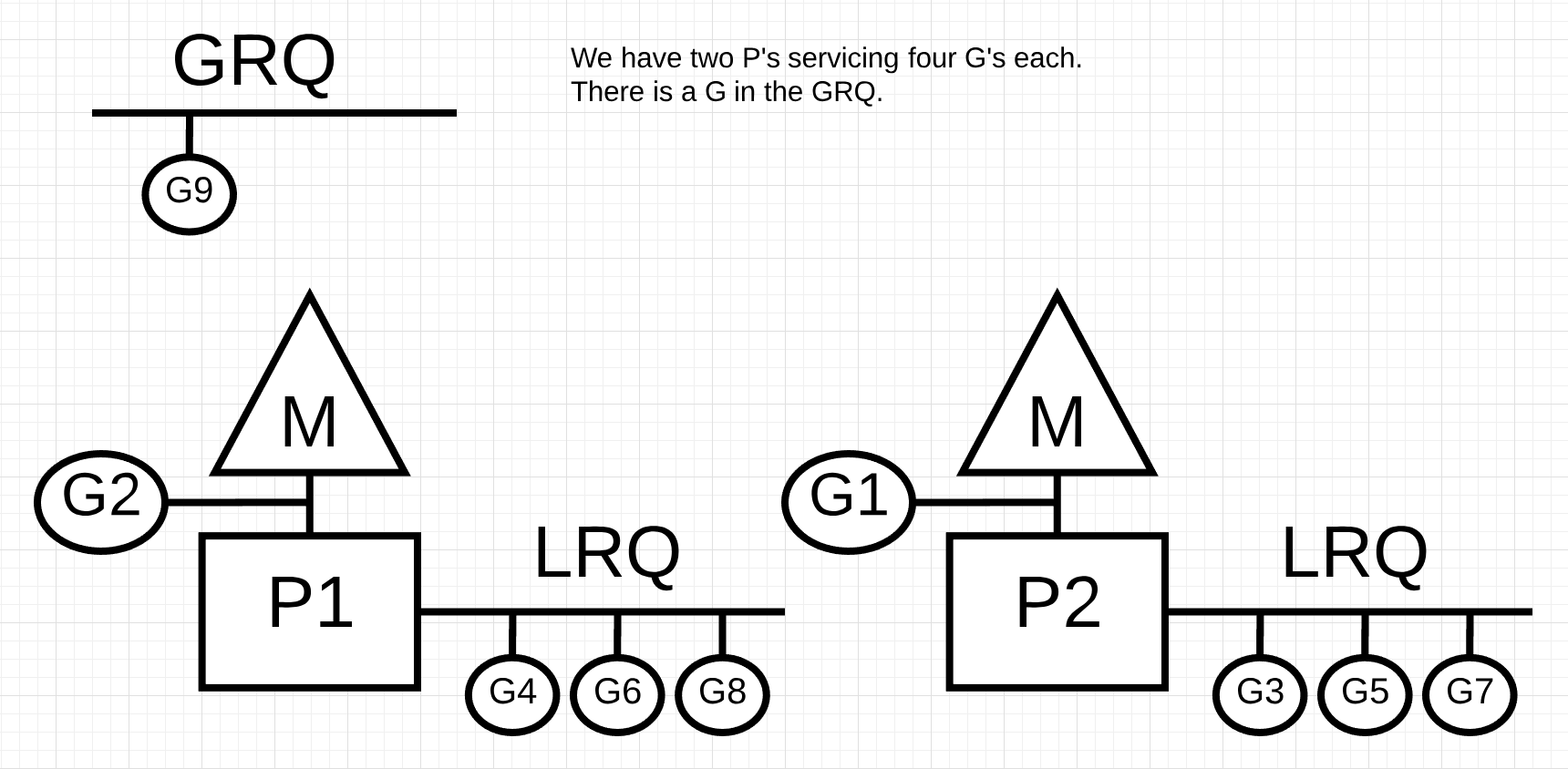
그림 9에서 두 개의 P가 각각 4개의 고루틴을 처리하고 GRQ에 1개의 코루틴이 있는 Go 프로그램이 있습니다. P중 하나가 모든 고루틴을 빨리 처리해버리면 어떻게 될까요?
그림 10
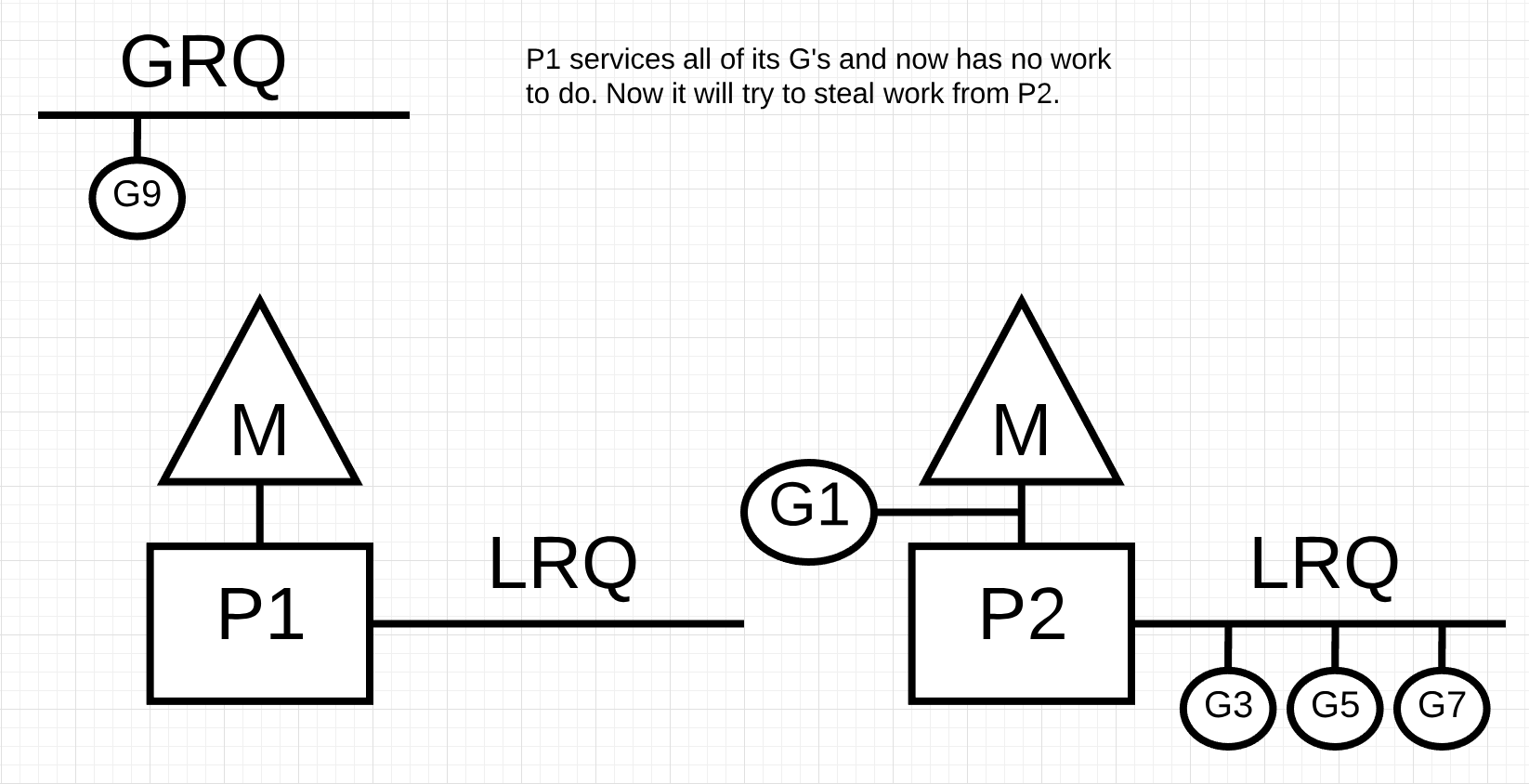
그림 10에서 P1에는 실행할 고루틴이 더 이상 없습니다. 하지만 P2의 LRQ와 GRQ에는 실행 가능한 고루틴들이 있습니다. 이것은 P1이 작업을 훔칠 필요가 있는 순간입니다. 작업 훔치기에 대한 규칙은 다음과 같습니다.
Listing 2
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
Listing 2의 규칙에 따라 P1은 P2의 LRQ에서 고루틴들을 확인하고 절반을 가져와야 합니다.
그림 11
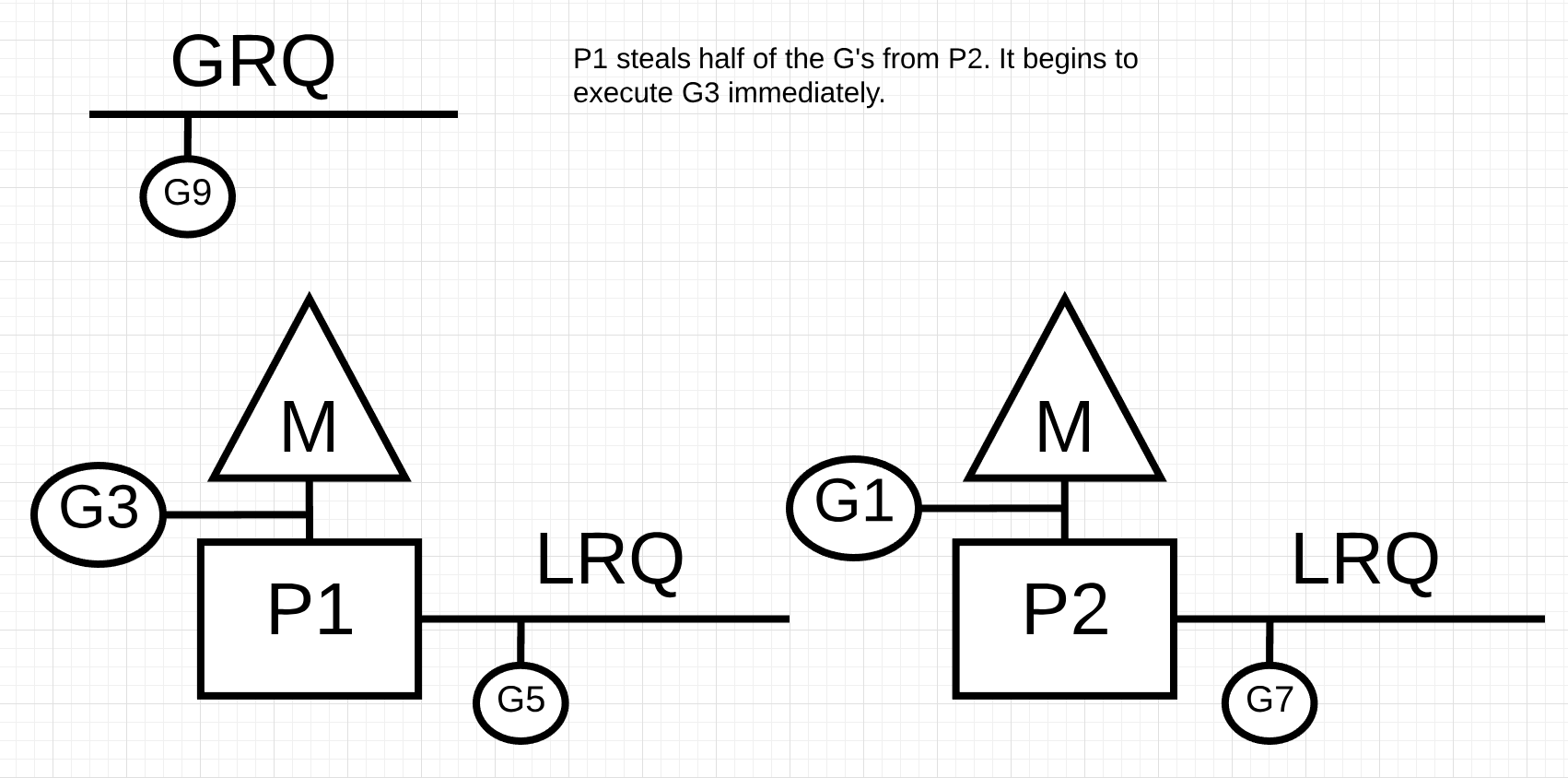
그림 11에서, 고루틴의 절반이 P2에서 가져와졌고 P1은 이제 그 고루틴들을 실행할 수 있습니다.
P2가 모든 고루틴을 종료하고 P1에 LRQ가 남아있지 않으면 어떻게 될까요?
그림 12
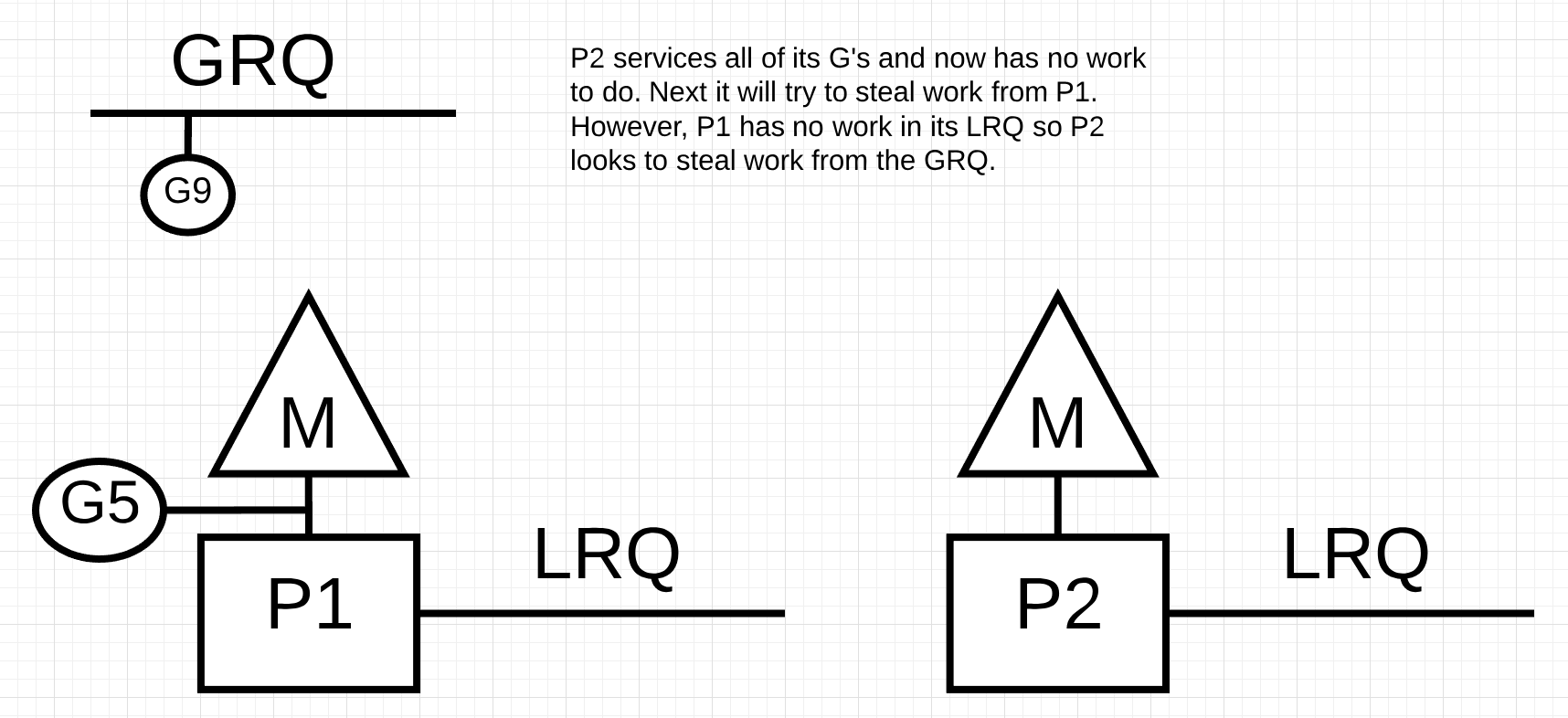
그림 12에서, P2는 모든 작업을 마치고 작업 훔치기가 필요하게 되었습니다. 먼저, P1의 LRQ를 보지만 어떤 고루틴도 찾을 수 없었습니다. 다음으로 GRQ를 확인하여, 고루틴 9를 찾았습니다.
그림 13
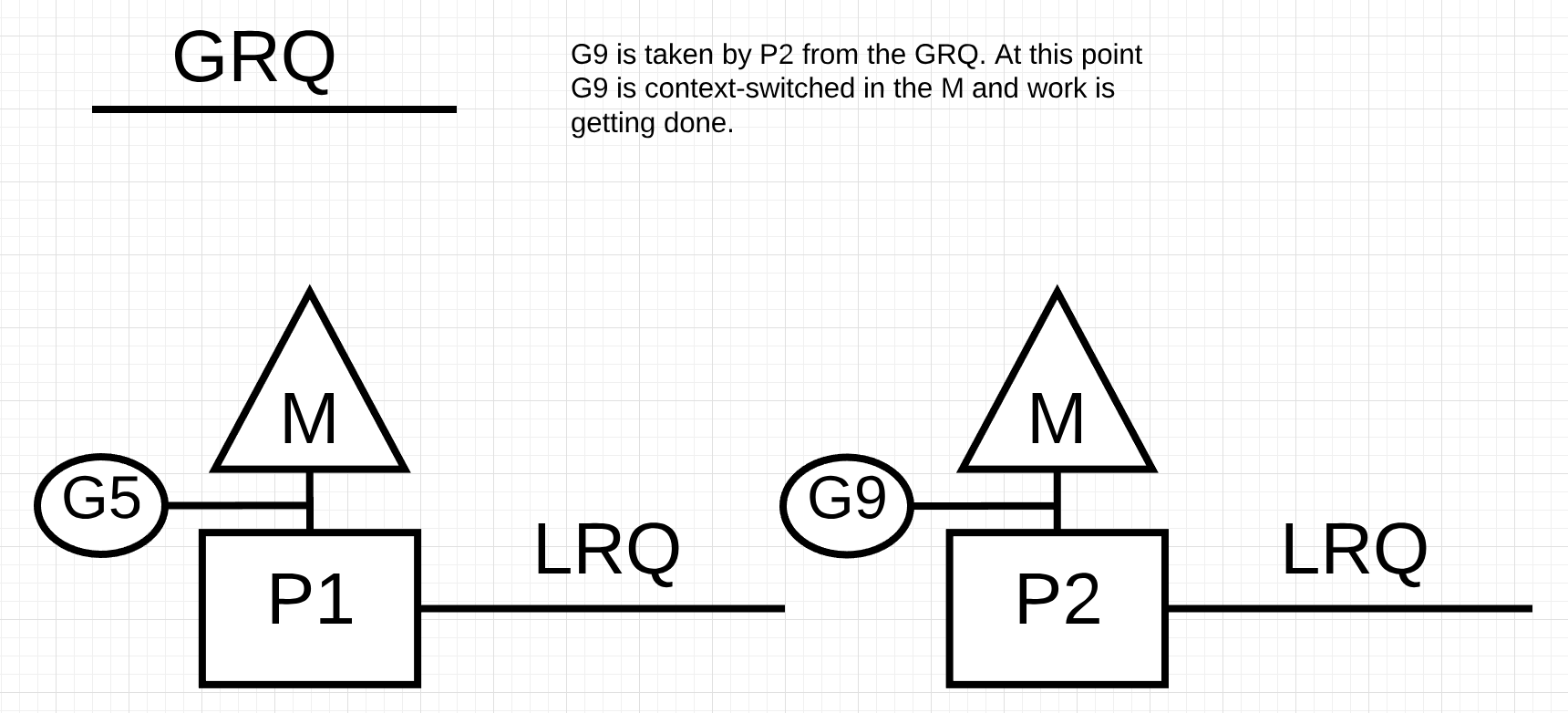
그림 13에서, P2는 GRQ에서 고루틴 9를 훔쳐서 작업을 시작합니다. 훌륭한 점은 작업 훔치기가 M을 지속적으로 쉬지않고 일하게 한다는 것입니다. 작업 훔치기는 내부적으로 M을 스피닝하는 것으로 간주됩니다. 이 스피닝의 다른 장점은 JBD가 작업 훔치기 포스트에서 설명하는 다른 장점들도 가집니다.
실용 사례
원리와 의미론을 이용하여, 저는 어떻게 이 모든 것이 Go 스케줄러가 시간이 지남에 따라 더 많은 일을 하게 하는지 보여드리고자 합니다. C로 작성된 멀티쓰레드 애플리케이션이 메시지를 앞뒤로 전달하는 두 개의 OS 쓰레드를 가지고 있다고 생각해보십시오.
그림 14
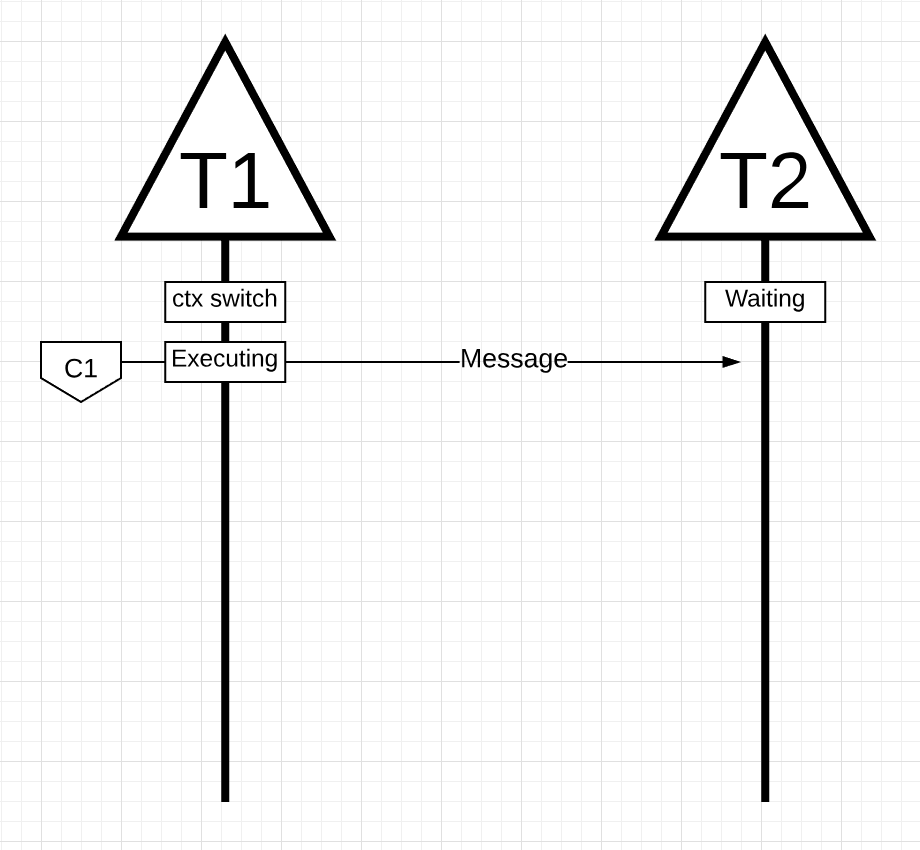
그림 14에서 메시지를 앞뒤로 전달하는 2개의 쓰레드가 있습니다. 쓰레드 1은 코어 1에서 컨텍스트 스위치를 얻고 쓰레드 1에서 쓰레드 2에 메시지를 보낼 수 있도록 실행 중입니다.
참고: 메시지 전달 방법은 중요하지 않습니다. 중요한 것은 오케스레이션이 진행되는 동안의 쓰레드 상태입니다.
그림 15
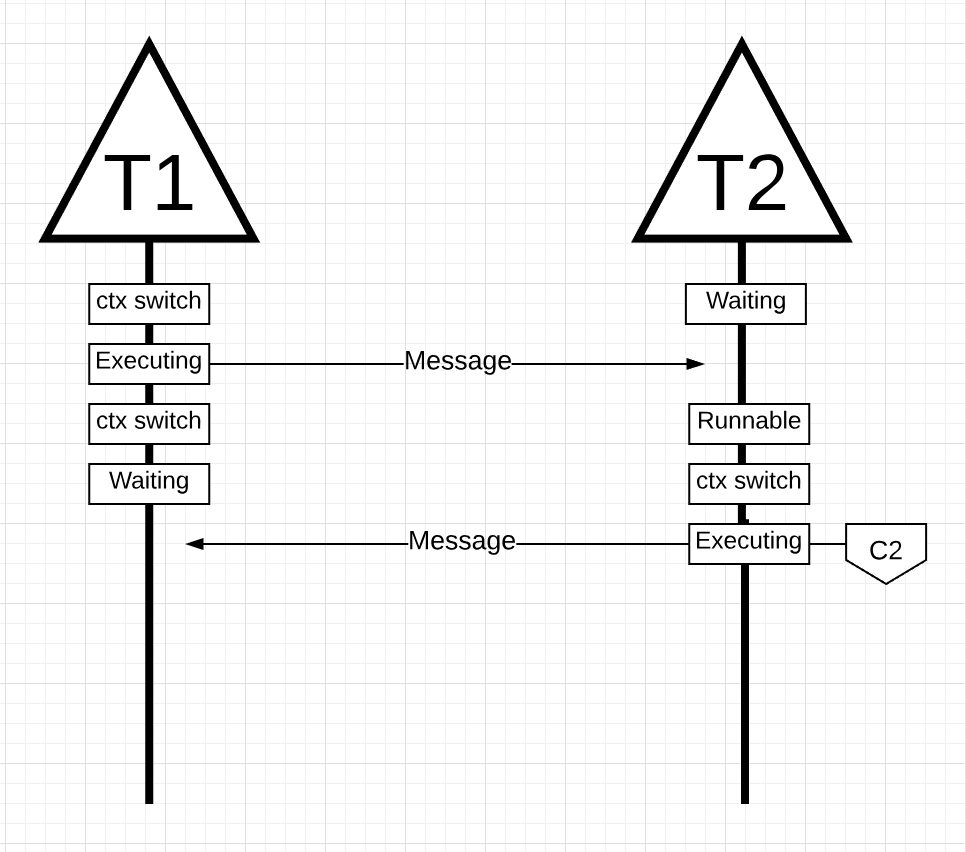
그림 15에서, 쓰레드 1이 메시지 전송을 마치면 응답을 기다려야 합니다. 그러면 쓰레드 1이 코어 1에서 컨텍스트 스위칭되어 대기 상태가 됩니다. 쓰레드 2가 메시지를 받으면, 실행가능 상태가 됩니다. 이제 OS는 컨텍스트 스위칭을 수행아여 쓰레드 2를 코어 2에서 실행합니다. 다음에 쓰레드 2는 새로운 메시지를 쓰레드 1로 보냅니다.
그림 16
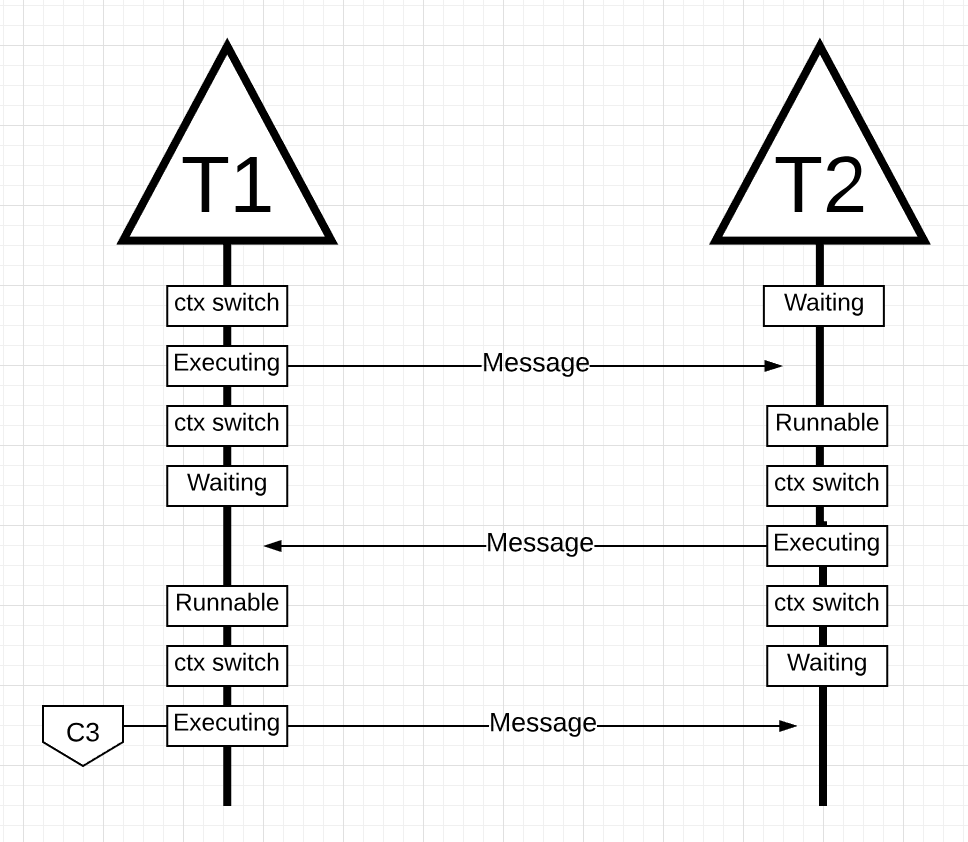
그림 16에서, 쓰레드 2에 의한 메시지가 쓰레드 1에 의 해 수신됨에 따라 컨텍스트 스위칭이 다시 생깁니다. 이제 쓰레드 2가 대기상태로 전환되고 쓰레드 1이 실행가능 상태로 전환되어 메시지를 다시 보냅니다.
이러한 모든 컨텍스트 스위칭과 상태변경은 작업속도를 제한하는 수행시간을 필요로 합니다. 각 컨텍스트 스위칭으로 50나노초의 대기시간이 발생하고, 하드웨어가 나노초당 12개의 명령어를 실행하면 600개 가량의 명령어가 컨텍스트 스위칭 중 실행되지 못합니다. 만약 이 쓰레드가 서로 다른 코어에 있다면 캐시라인 누락으로 인한 추가 지연 발생 가능성도 높아집니다.
이 예제를 고루틴과 Go 스케줄러를 이용해 확인해봅시다.
그림 17
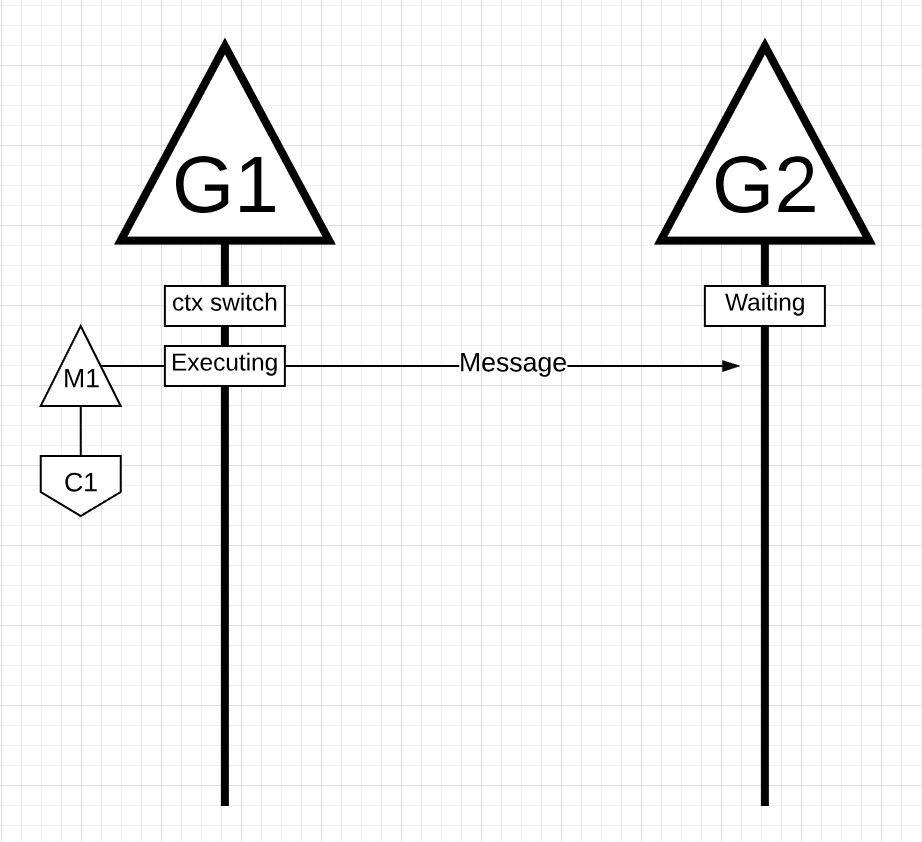
그림 17에서, 메시지를 앞뒤로 오케스트레이션하는 두 개의 고루틴이 있습니다. G1은 코어 1에서 실행되는 M1에 컨텍스트 스위칭되어, G1에서 G2로 메시지를 보내는 작업을 진행합니다.
그림 18
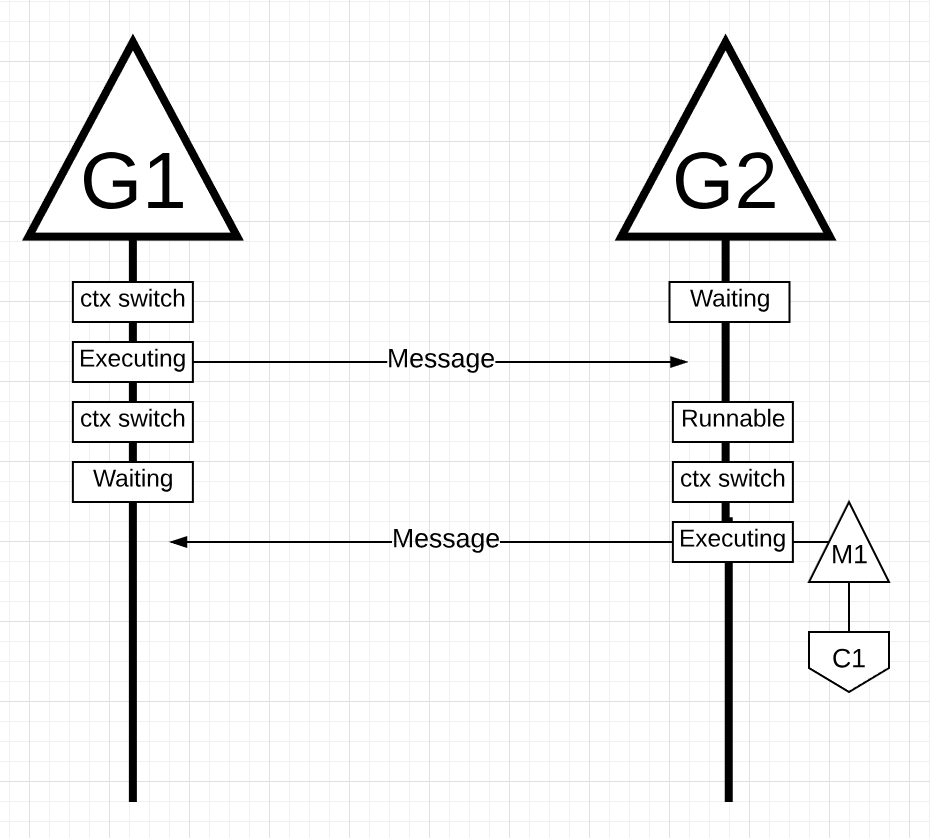
그림 18에서, G1이 메시지를 보내고, M1에서 컨텍스트 스위칭 되어 대기 상태가 됩니다. G2가 메시지를 받으면 진행가능 상태가 됩니다. 고 스케줄러는 G2를 M1으로 컨텍스트 스위칭하여 코어 1에서 실행시킵니다. 다음으로 G2는 메시지른 G1으로 다시 보냅니다.
그림 19
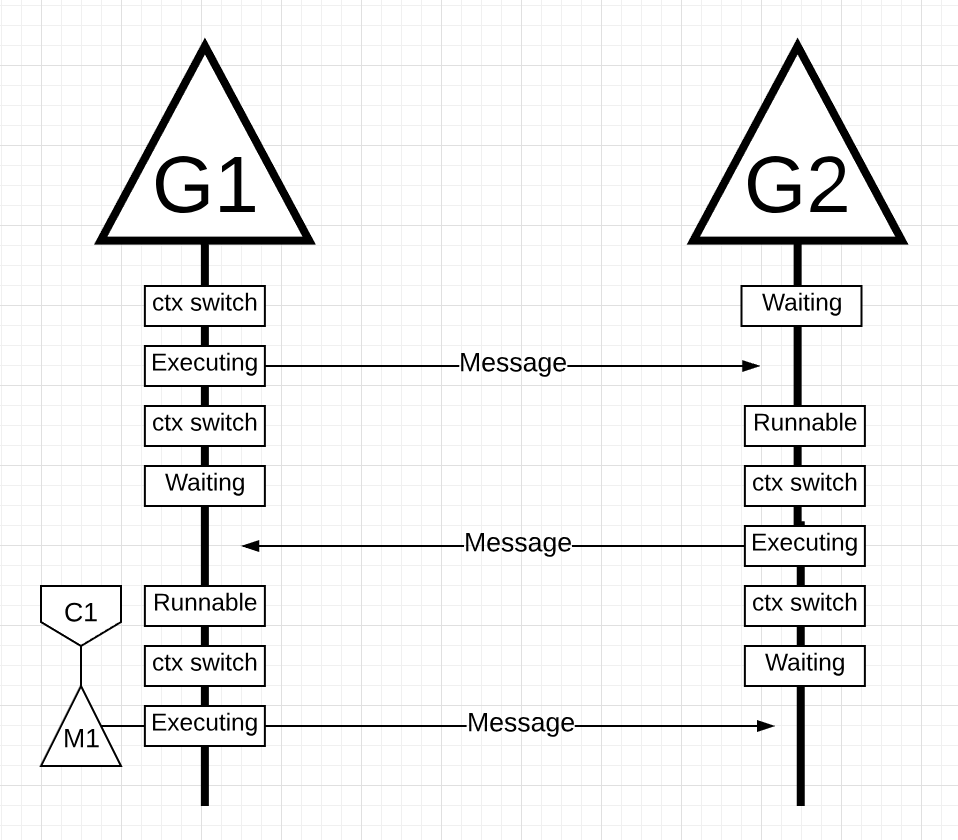
그림 19에서, 메시지가 G2에서 G1으로 보내져 컨텍스트 스위치가 다시 일어납니다. 이제 G2는 실행 상태에서 대기 상태로 G1은 대기 상태에서 실행가능 상태로 컨택스트 스위칭되고, 새 메시지를 다시 보낼 수 있게 됩니다.
겉으로는 전혀 다른 것처럼 보이지 않습니다. 쓰레드를 사용하든 고루틴을 사용하든 동일한 컨텍스트 스위칭과 상태 변경이 발생합니다. 그러나 쓰레드와 고루틴에는 눈에 잘 띄지 않는 큰 차이가 있습니다.
고루틴을 사용할 경우, 동일한 OS 쓰레드와 코어가 처리에 사용됩니다. 이것은 OS의 관점에서 보았을 때 OS 쓰레드가 한번도 대기 상태가 되지 않았다는 것을 의미합니다. 결과적으로 쓰레드를 사용할 때 손실된 명령어들이 고루틴을 사용할 때는 손실되지 않았습니다.
근본적으로, Go는 OS 수준의 IO 블로킹 작업을 CPU작업으로 변환시킵니다. 애플리케이션에서 컨텍스트 스위칭이 발생하기 때문에, 우리는 쓰레드를 사용할 때 발생하는 컨텍스트 스위칭당 평균 600개의 명령어 손실을 예방할 수 있습니다. 스케줄러는 또한 캐시라인 효율성과 NUMA에 도움이 됩니다. 이것이 우리가 가상 코어보다 쓰레드를 더 필요로 하지 않는 이유입니다. Go에서는 스케줄러가 더 작은 쓰레드를 쓰고 각 쓰레드가 더 많은 일을 해서, OS와 하드웨어의 부하를 줄이기 때문에, 더 많은 작업을 완료할 수 있습니다.
결론
Go 스케줄러는 OS와 하드웨어가 어떻게 동작하는 지에 대한 복잡성을 고려할 때 놀랍습니다. OS 수준에서 IO 블로킹 작업을 CPI 작업으로 전환하는 기능은 더 많은 CPU 자원을 활용하는데 큰 도움이 됩니다. 이것은 가상 코어보다 많은 OS 쓰레드가 필요하지 않은 이유입니다. 모든 작업(CPU와 IO블로킹)이 가상코어당 하나의 쓰레드로 동작할 것이라 기대할 수 있습니다. 이것은 네트워킹 애플리케이션과 OS 쓰레드를 블록하는 시스템 호출이 없는 다른 애플리케이션에서도 가능합니다.
개발자로서, 당신은 처리하는 작업 종류에 따라 애플리케이션이 하는 일을 이해해야 합니다. 무제한의 고루틴을 만들고 놀라운 성능을 기대할 수는 없습니다. Less is always more, 하지만 고루틴의 의미를 이해하면 더 나은 엔지니어링 결정을 내릴 수 있습니다. 다음 글에서는, 동시성을 보수적인 방법으로 활용하여 성능을 향상시키면서 코드에 추가되는 복잡성과 균형을 유지하는 아이디어를 살펴보겠습니다.