(번역) Go 스케줄링 파트 1
원문: https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
프렐류드
Go 스케줄러의 구조와 의미 이해를 제공하는 3부작의 세 번째 글입니다. 이 글은 OS 스케줄러에 중점을 둡니다.
세 시리즈의 인덱스:
서론
Go 스케줄러의 설계 및 동작을 통해 멀티스레드 Go 프로그램을 보다 효율적이고 빠르게 사용할 수 있습니다. 이는 Go 스케줄러가 운영체제(OS) 스케줄러에 대해 갖는 구조적 공감 덕분입니다. 그러나 당신의 멀티쓰레드 Go 소프트웨어의 설계와 동작이 스케줄러의 작동 방식에 구조적으로 공감하지 않는다면 아무 소용이 없습니다. OS와 Go 스케줄러가 어떻게 작동하는지에 대한 이해를 가지고 멀티쓰레드 소프트웨어를 올바르게 설계하는 것이 중요합니다.
이 글들에서는 스케줄러의 상위 레벨 구조 및 의미에 중점을 두어 설명합니다. 저는 당신이 동작을 시각화하여 보다 나은 엔지니어링 결정을 내릴 있도록 충분한 세부 사항을 제공할 예정입니다. 비록 멀티쓰레드 애플리케이션을 만들기 위해 많은 엔지니어링 결정사항이 있지만, 구조와 의미로은 기초지식의 중요한 부분을 현성합니다.
OS 스케줄러
운영체제 스케줄러는 복잡한 소프트웨어입니다. 스케줄러는 실행되는 하드웨어의 상태와 설정을 고려해야 합니다. 여기에는 다중 프로세서 및 코어, CPU 캐시 및 NUMA의 존재가 포함되며 이에 국한되지 않습니다. 이 지식이 없으면, 스케줄러는 최대한 효과적으로 동작할 수 없습니다. 훌륭한 점은 이들 주제에 깊이 빠지지 않고 OS 스케줄러가 어떻게 동작하는지에 대한 좋은 모델을 개발할 수 있다는 것입니다.
프로그램은 순차적으로 실행해야하는 일련의 기계 명령어일 뿐입니다. 이를 실현하기 위해 운영체제는 쓰레드를 사용합니다. 할당된 명령어 세트를 순차적으로 실행하는 것은 스레드의 일입니다. 더이상의 명령어가 없을 때까지 쓰레드는 지속적으로 실행합니다. 이것이 제가 쓰레드를 “a path of execution"이라고 부르는 이유입니다.
모든 프로그램은 프로세스를 만들고 각 프로세스는 초기 쓰레드가 제공됩니다. 쓰레드는 더 많은 쓰레드를 생성할 수 있습니다. 서로 다른 스레드는 독립적으로 실행되며 스케줄 결정은 프로세스 레벨이 아닌 스레드 레벨에서 수행됩니다. 쓰레드는 동시(하나의 코어에서 실행) 또는 병렬(여러 코어에서 실행)로 실행될 수 있습니다. 쓰레드는 안전하고 지역적인 상태를 유지하고, 독립적인 명령어 실행을 보장합니다.
운영체제 스케줄러는 실행할 수 있는 쓰레드가 있는 한 코어가 쉬지 않게 할 책임을 가집니다. 또한 모든 쓰레드가 동시에 실행되는 환상을 만들어야 합니다. 이 환상을 만드는 과정에서 스케줄러는 우선순위가 높은 쓰레드를 실행해야 합니다. 하지만, 우선순위가 낮은 쓰레드가 실행시간 고갈을 겪어서는 안됩니다. 또한 스케줄러는 빠르고 현명한 결정을 내려 스케줄링 대기시간을 최소화해야 합니다.
이런 일이 일어나기 위해서는 많은 알고리즘이 필요하지만, 다행히도 업계에서 수십 년의 노력과 경험을 활용할 수 있습니다. 이 모든 것을 더 잘 이해하려면 중요한 몇 가지 개념을 설명하고 정의할 필요가 있습니다.
명령어 실행
때로는 instruction pointer(IP)라고도 하는 program counter(PC)는 쓰레드가 다음에 실행할 명령을 추적할 수 있도록 합니다. 대부분의 프로세서에서 PC는 현재 명령어가 아니라 다음 명령어를 가리킵니다.
그림 1
 https://www.slideshare.net/JohnCutajar/assembly-language-8086-intermediate
https://www.slideshare.net/JohnCutajar/assembly-language-8086-intermediate
Go 프로그램에서 스택 트레이스를 본 적이 있다면 각 줄 끝의 작은 16진수를 발견했을 것입니다. Listing 1에서 +0x39와 + 0x72를 찾아보십시오.
Listing 1
goroutine 1 [running]:
main.example(0xc000042748, 0x2, 0x4, 0x106abae, 0x5, 0xa)
stack_trace/example1/example1.go:13 +0x39 <- LOOK HERE
main.main()
stack_trace/example1/example1.go:8 +0x72 <- LOOK HERE
이 숫자는 함수의 상단에서부터의 PC값을 나타냅니다. +0x39 PC 오프셋은 example 함수가 실행할 다음 명령어을 나타냅니다. +0x72 PC 오프셋은 제어가 main 함수로 컨트롤이 넘어왔을 때 실행할 다음 명령어를 나타냅니다. 중요한 점은 그 앞부분을 확인하여 어떤 명령어가 실행되었는지 알 수 있는 것입니다.
Listing 1의 스택 트레이스를 발생시킨 Listing 2를 봅시다.
Listing 2
https://github.com/ardanlabs/gotraining/blob/master/topics/go/profiling/stack_trace/example1/example1.go
07 func main() {
08 example(make([]string, 2, 4), "hello", 10)
09 }
12 func example(slice []string, str string, i int) {
13 panic("Want stack trace")
14 }
16진수 +0x39는 함수의 시작 명령어보다 57(10진수) 바이트 아래에있는 example 함수 내부의 명령어에 대한 PC 오프셋을 나타냅니다. 아래 Listing 3에서는 example 함수 바이너리의 objdump를 볼 수 있습니다. 아래쪽에 나열된 12번째 명령어를 찾으십시오. 해당 명령어 위의 코드 행이panic에 대한 호출임을 주목하십시오.
Listing 3
$ go tool objdump -S -s "main.example" ./example1
TEXT main.example(SB) stack_trace/example1/example1.go
func example(slice []string, str string, i int) {
0x104dfa0 65488b0c2530000000 MOVQ GS:0x30, CX
0x104dfa9 483b6110 CMPQ 0x10(CX), SP
0x104dfad 762c JBE 0x104dfdb
0x104dfaf 4883ec18 SUBQ $0x18, SP
0x104dfb3 48896c2410 MOVQ BP, 0x10(SP)
0x104dfb8 488d6c2410 LEAQ 0x10(SP), BP
panic("Want stack trace")
0x104dfbd 488d059ca20000 LEAQ runtime.types+41504(SB), AX
0x104dfc4 48890424 MOVQ AX, 0(SP)
0x104dfc8 488d05a1870200 LEAQ main.statictmp_0(SB), AX
0x104dfcf 4889442408 MOVQ AX, 0x8(SP)
0x104dfd4 e8c735fdff CALL runtime.gopanic(SB)
0x104dfd9 0f0b UD2 <--- LOOK HERE PC(+0x39)
Remember: PC는 이번 명령어가 아닌 다음 명령어입니다. Listing 3은 Go 프로그램용 쓰레드가 실행을 책임지는 것을 보여주는 amd64 기반 명령어의 좋은 예입니다.
쓰레드 상태
또다른 중요한 개념은 스케줄러와 쓰레드의 역할을 결정하는 쓰레드 상태입니다. 쓰레드는 대기, 실행가능, 실행 세가지 상태 중 하나일 수 있습니다.
대기: 멈춘 상태로 기다리는 것을 의미합니다. 하드웨어(디스크, 네트워크), 운영체제(시스템 호출), 동기화 호출(atomic, mutex) 등이 이유일 수 있습니다. 이러한 유형의 지연은 성능저하의 근본 원인입니다.
실행가능: 코어 사용시간을 요구하는 상태로 기계 명령어를 실행할 수 있음을 의미합니다. 여러 쓰레드가 코어 사용시간을 요구할 경우, 쓰레드는 오랜 시간을 기다려야 합니다. 또한 개별 쓰레드의 사용시간은 단축되어 쓰레드가 사용시간을 두고 경쟁하게 됩니다. 이러한 유형의 스케줄링 지연은 성능저하를 유발합니다.
실행: 쓰레드가 코어에 할당도어 기계 명령어를 실행중임을 나타냅니다. 모두가 원하는 상태입니다.
작업의 유형
쓰레드가 할 수 있는 작업에는 두가지 유형이 있습니다. 첫째는 CPU-Bound 이며 두번째는 IO-Bound입니다.
CPU-Bound: 쓰레드를 대기 상태로 절대로 변경시키지 않는 작업입니다. 이 작업은 지속적으로 연산을 합니다. 파이의 N번째 자릿수를 계산하는 쓰레드는 CPU-Bound가 됩니다.
IO-Bound: 이것은 쓰레드를 대기 상태로 변경시키는 작업입니다. 이 작업은 네트워크를 통해 리소스에 접근하거나 시스템 호출을 운영체제로 보내는 작업입니다. 데이터베이스에 접근해야 하는 쓰레드는 IO-Bound가 됩니다. 쓰레드를 대기하게 하는 동기 이벤트(atomic, mutex)도 이에 포합됩니다.
컨텍스트 스위칭
만약 당신이 리눅스, 맥 또는 윈도우즈를 사용한다면 강탈형 스케줄러를 사용하는 OS를 사용하는 것입니다. 이것은 몇가지 중요한 것을 의미합니다. 첫째로, 스케줄러는 특정 쓰레드가 주어진 시간내에 실행될 것에 대해 보장하지 않는다는 것을 의미합니다. 이벤트에 의한 쓰레드 우선순위(예: 네트워크에서 데이터 수신)는 스케줄러가 언제 어떤 쓰레드를 선택할지 결정할 수 없게 합니다.
두번째로, 운에 의해 동작한 것을 기반으로 코드를 작성하면 안된다는 것을 의미합니다. 이런 동작이 일어나는 것을 1000회 이상 보았기 때문에 이것이 동작할 것이라고 생각하기 쉽습니다. 애플리케이션에서 보장이 필요할 경우 꼭 쓰레드 동기화와 오케스트레이션을 제어해야 합니다.
코어에서 쓰레드를 교환하는 행위를 컨텍스트 스위치라고 합니다. 컨텍스트 스위치는 실행 쓰레드를 코어에서 끌어와서 실행가능 쓰레드로 대체할 때 발생합니다. 실행 큐에서 선택된 쓰레드가 실행 상태로 이동합니다. 끌어온 쓰레드는 실행가능 상태(가능할 경우), 또는 대기 상태(IO-Bound 작업에 의해 대체되었을 경우)로 이동할 수 있습니다.
켄텍스트 스위치는 쓰레드를 코어에서 교환하는 데 시간이 걸리기 때문에 비용이 많이 듭니다. 지연시간은 요인에 따라 다르지만 ~50 에서 ~100 나노세컨드 이상이 걸립니다. 하드웨어가 코어별 나노세컨드당 12명령어를 처리한다면(평균적으로), 컨텍스트 스위치는 ~600 에서 ~1200 지연을 발생시킵니다. 본질적으로 프로그램은 컨텍스트 스위칭 중에 많은 수의 명령어를 실행할 수 있는 능력을 잃어버립니다.
IO-Bound 작업에 중점을 둔 프로그램을 가지고 있다면 컨텍스트 스위치가 장점이 될 것입니다. 일단 쓰레드가 대기 상태가 되면 실행가능 상태에 있는 다른 쓰레드가 그 자리를 차지합니다. 이렇게 하면 코어가 항상 작업을 수행할 수 있습니다. 이것은 스케줄링의 가장 중요한 측면 중 하나입니다. 실행해야 할 작업(실행가능 상태인 쓰레드)이 있으면 코어를 쉬게 하지 않습니다.
프로그램이 CPU-Bound 작업이라면, 컨텍스트 스위치는 성능에 악몽이 됩니다. 쓰레드는 항상 해야할 작업이 있기 때문에 컨텍스트 스위칭은 그 작업의 진행을 중단시킵니다. 이 상황은 IO-Bound 작업에서 발생하는 상황과 완전히 대조됩니다.
Less Is More
프로세서에 코어가 하나 뿐인 초기에는, 스케줄링이 지나치게 복잡해지지 않았습니다. 단일 코어를 사용하는 단일 프로세가 있기 때문에, 오직 하나의 쓰레드만 실행될 수 있었습니다. 아이디어는 단일 코어 스케줄러 기간을 정의하고 모든 실행 쓰레드를 그 기간동안만 실행하는 것이었습니다.
예를 들어 스케줄러 기간은 10ms(밀리초) 두개의 쓰레드가 있으면 각 쓰레드는 5ms를 가집니다. 만약 5개의 쓰레드가 있으면 각각 2ms를 가집니다. 하지만 100개의 쓰레드가 있으면 어떻게 될까요? 컨텍스트 스위치에 많은 시간을 소비하기 때문에 각 쓰레드에 10μs(마이크로초)의 기간을 주는 것은 의미가 없습니다.
당신에게 필요한 것은 시간 조각이 얼마나 적어질 수 있는제 제한하는 것입니다. 마지막 시나리오에서 최소 기간 슬라이스가 2ms이고 쓰레드 수가 100개인 경우 스케줄러 기간은 2000ms 또는 2s(초)로 증가해야 합니다. 1000개의 쓰레드가 있다면, 이제는 20초의 스케줄러 기간은 20초로 늡니다. 각 쓰레드가 시간조각을 최대로 사용하는 경우 간단한 예제에서 모든 쓰레드가 한 번 실행되는 데 20초가 걸립니다.
이것이 동작에 대한 축약이라는 것을 명심하십시오. 스케줄링을 할 때 스케줄러가 고려하고 처리해야 할 많은 것들이 있습니다. 당신은 애플리케이션에서 사용하는 쓰레드의 수를 제어합니다. 고려할 쓰레드가 많고, IO-Bound 작업이 일어날수록 더 많은 혼돈과 비결정적 동작이 생깁니다. 결과로 스케줄링과 실행이 긴 시간이 걸립니다.
이것이 “Less is More"인 이유입니다. 실행가능 상태의 쓰레드가 적으면 스케줄링 오버헤드가 적어지고 더많은 시간을 개별 쓰레드가 가집니다. 실행가능 상태의 쓰레드가 많을수록 더 적은 시간을 개별 쓰레드가 가집니다. 이는 시간이 지남에 따라 작업량이 주는 것을 의미합니다.
균형을 찾기
애플리케이션이 최고의 처리량을 얻기 위해 보유하고 있는 코어 수와 필요로 하는 쓰레드 수의 균형을 찾아야 합니다. 이 균형을 관리할 때 쓰레드 풀은 훌륭한 대답입니다. Go와 함께라면 이것이 더 이상 필요하지 않다는 것을 보여줄 것입니다. 나는 이것이 Go가 멀티쓰레드 애플리케이션 개발을 더 쉽게 만들어 주는 좋은 이유 중 하나라고 생각합니다.
Go에서 코딩하기 전에, 나는 NT에서 C++과 C#으로 코드를 작성했습니다. 이 운영체제에서 IOCP(IO Completion Ports) 쓰레드 풀의 사용은 멀티쓰레드 소프트웨어 사용에 중요했습니다. 엔지니어로서 처리랴을 최대화하기 위해 쓰레드 풀 수와 풀당 최대 쓰레드 수를 파악하는 것이 필요합니다.
데이터베이스를 사용하는 웹 서비스를 작성할 때 코어당 3개의 쓰레드는 항상 NT에서 최고의 처리량을 제공하는 것처럼 보였습니다. 다시 말해, 코어당 3개의 쓰레드는 컨텍스트 스위칭의 지연비용을 최소화하며 코어의 실행시간을 최대화합니다. IOCP 쓰레드 풀을 생성할 때, 호스트 머신의 모든 코어에 대해 최소 1개의 쓰레드와 최대 3개의 쓰레드로 시작한다는 것을 알았습니다.
만약 코어당 2개 쓰레드를 사용했다면 작업완료를 대기시간이 있기 때문에, 총 작업 완료애 더 오랜 시간이 걸렸습니다. 만약 코어당 4개 쓰레드를 사용했다면 컨텍스트 스위치에 많은 대기시간이 있었기 때문에 더 오랜 시간이 걸렸습니다. 어떤 이유로든 코어당 3개의 쓰레드의 균형은 항상 NT의 매직넘버인 것처럼 보였습니다.
당신의 서비스가 여러 종류의 작업을 한다면 어떻습니까? 그러면 대기 시간이 각각 달라질 수 있습니다. 어쩌면 처리해야할 시스템 레벨 이벤트를 생성할 수도 있습니다. 모든 다른 종류의 작업 부하에 대해 항상 작동하는 매직넘버를 찾는 것이 불가능할 수도 있습니다. 서비스의 성능을 튜닝하기 위해 쓰레드 풀을 사용할 때에는 옵라르고 일관성있는 구성을 찾기가 매우 복잡할 수 있습니다.
캐시 라인
메인 메모리에서 데이터에 접근하는데는 높은 대기비용(~100에서 ~300 클럭 싸이클)이 듭니다. 캐시에서 데이터에 접근하는 것은 캐시에 따라 훨씬 낮은 비용(~3에서 ~40 클럭 싸이클)이 듭니다. 오늘날, 성능의 한 측면은 데이터 접근 지연을 줄이기 위해 얼마나 효율적으로 데이터를 프로세서로 가져올 수 있는지에 관한 것입니다. 상태를 변경시키는 멀티쓰레드 애플리케이션을 작성하려면 캐싱 시스템의 작동방식을 고려해야 합니다.
그림 2

캐시 라인을 이용하여 프로세서와 메인 메모리 간에 데이터가 교환됩니다. 캐시 라인은 메인 메모리와 캐싱 시스템 간에 교환되는 64바이트의 메모리입니다. 각 코에에는 필요한 캐시 라인의 사본이 주어지며, 이는 하드웨어가 value semantics를 사용함을 의미합니다. 이것이 멀티 쓰레드 애플리케이션에서 메모리로의 변이가 성능 악몽을 불러 일으킬 수 있는 이유입니다.
병렬로 실행중인 여러 쓰레드가 동일한 데이터 값 또는 서로 가까운 데이터 값에 접근하는 경우 동일한 캐시 라인의 데이터에 접근하게 됩니다. 코어에서 실행되는 쓰레드는 동일한 캐시 라인의 사본을 가지게 됩니다.
그림 3
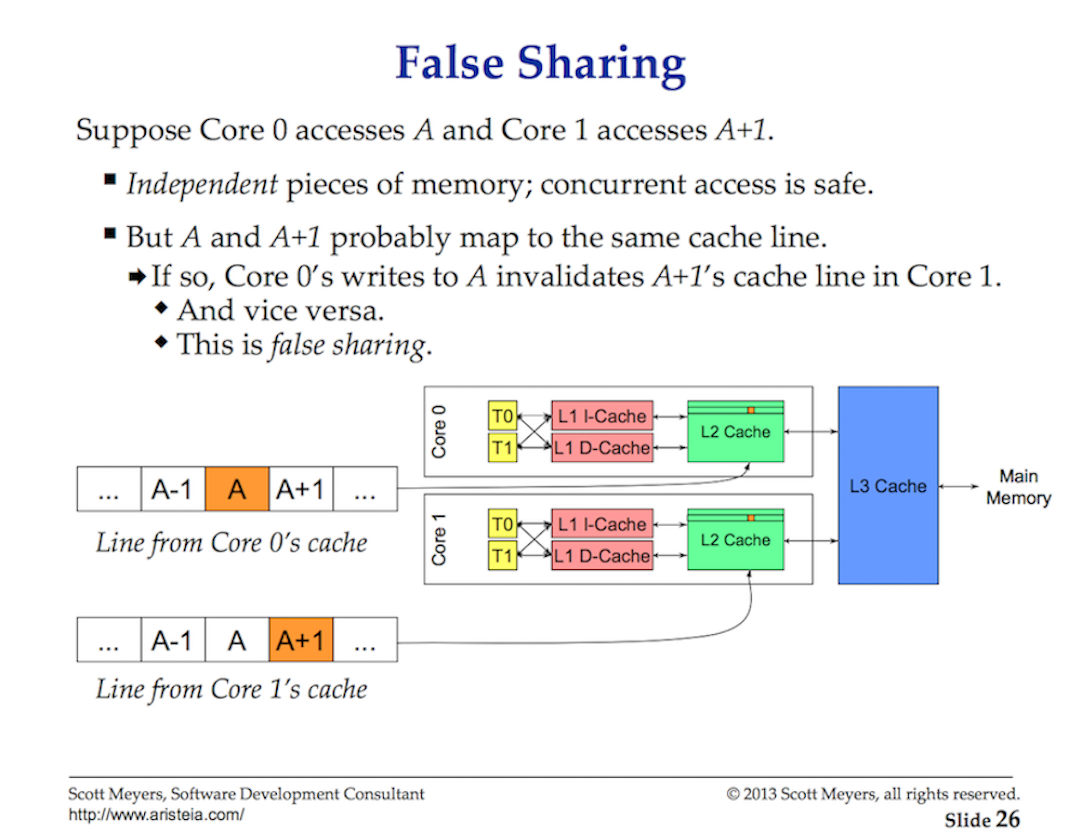
만약 한 쓰레드가 캐시 라인의 복사본을 변경하면, 하드웨어의 마법을 통해, 동일한 캐시 라인의 다른 모든 복사본을 더티 표시해야 합니다. 쓰레드가 더티 캐시 라인에 대한 읽기 또는 쓰기 접근을 시도하면 캐시 라인의 새 복사본을 얻기 위해 메모리 접근(~100에서 ~300 클럭 사이클)이 필요합니다.
아마도 2코어 프로세서에서 이것은 큰 문제가 아니지만 32코어 프로세서에서 32개의 쓰레드가 모두 동일한 캐시 라인의 데이터에 접근하고 변경하는 것은 어떻습니까? 각각 16개의 코어가 있는 2개의 물리적 프로세서가 있는 시스템은 어떻습니까? 프로세서 간 통신을 위한 대기시간이 추가되기 때문에 더 악화될 것입니다. 애플리케이션은 메모리 문제를 일으키고 성능은 끔찍할 것입니다. 그리고 아마도 왜 그런지 이해할 수 없을 것입니다.
이를 cache-coherency problem이라고 하며 false sharing과 같은 문제가 발생합니다. 변경되는 공유 상태를 가진 멀티쓰레드 애플리케이션을 작성할 때, 캐싱 시스템은 고려되어야 합니다.
스케줄링 결정 시나리오
제가 당신에게 알려주 고급 정보를 기반으로 OS 스케줄러를 작성하라고 요청했다고 가정해보십시오. 고려해야할 시나리오를 생각해보십시오. 스케줄러가 스케줄링을 결정할 때 고려해야 하는 많은 것들 중 하나라는 것을 기억하십시오.
애플리케이션을 시작하면 메인 쓰레드가 만들어져 코어1에서 실행됩니다. 쓰레드가 명령을 실행할 때 데이터가 필요하기 때문에 캐시 라인을 검색하고 있습니다. 쓰레드는 이제 동시처리를 위해 쓰레드를 작성하기로 결정합니다. 여기에 질문이 있습니다.
쓰레드가 생성되고 준비되면, 스케줄러는 다음을 수행해야 합니다:
- 코어1에서 메인쓰레드를 끄고 컨텍스트 스위칭을 합니까? 이렇게 하면 성능을 향상시킬 수 있습니다. 새로운 쓰레드가 이미 캐시된 동일한 데이터를 필요로 할 가능성이 매우 높습니다. 그러나 메인 쓰레드는 모든 시간분배를 얻지 못합니다.
- 코어1이 메인 쓰레드에서 시간분배 완료될 때까지 기다릴 수 있습니까? 쓰레드가 실행되고 있지 않지만 데이터 가져오기에 대한 대기시간은 제거됩니다.
- 쓰레드가 다음 사용 가능한 코어를 기다리게 합니까? 이것은 코어의 캐시라인이 플러시되고, 검색되고, 복제되어 대기시간을 유발한다는 것을 의미합니다. 그러나 쓰레드가 더 빨리 시작하고 메인 쓰레드가 시간분배를 사용할 수 있습니다.
아직 재미있으신가요? 이것은 OS 스케줄러가 스케줄링 결정을 내릴 때 고려해야할 질문입니다. 다행히, 나는 그것을 만드는 사람이 아닙니다. 내가 말할 수 있는 것은 유휴 코어가 있는 경우 이것을 사용한다는 것입니다. 당신은 쓰레드가 실행가능할 때 실행되기를 원합니다.
결론
이 게시물의 첫 번째 부분에서는 멀티쓰레드 애플리케이션을 작성할 때 쓰레드 및 OS 스케줄러와 관련하여 고려해야 할 사항에 대한 통찰을 제공합니다. 이것은 Go 스케줄러가 고려해야 할 사항입니다. 다음 글에서는 Go 스케줄러의 의미와 이 스케줄러가 이 정보와 어떻게 관련되는지에 대해 설명할 것입니다. 마지막으로 두 가지 프로그램을 실행하여 이 모든 것을 실제로 보겠습니다.